2010-03-01[n年前へ]
■サーバ「新装開店」しました。 
 SQLサーバのハードディスクが読めなくなったので、これをきっかけに、サーバ構成を変えることにしました。秋葉原で部品を買い、新しくサーバを1台組んで、さっそく動かし始めまたところです。
SQLサーバのハードディスクが読めなくなったので、これをきっかけに、サーバ構成を変えることにしました。秋葉原で部品を買い、新しくサーバを1台組んで、さっそく動かし始めまたところです。
それと同時に、WEBアプリケーションを動かしているマシンの仮想化作業も終わりましたので、明日の今頃には、完全にサーバ構成を(これまでの環境をそのまま動かしつつ)仮想化環境で一新し、さらに停止させていた実験サーバも稼働再開させることができそうです。(参考情報)
アプリケーション・サーバの、移行には(これまた無料の)VMware vCenter converter を使っています。アプリケーション・サーバでたくさんのアプリケーションが起動しているのにも関わらず、その物理マシンを仮想化させることができる、ということには少し驚きました。しかも、メモリ不足で仮想メモリを使いまくりの、カリカリと音を 発するコンピュータなのに、そんな作業ができたということは、とても意外でした。
たとえば、日曜日(昨日)の午後にhirax.netにアクセスした方がいたならば、実はそのWEBサーバが受け答えをしているその最中(さなか)に、実はサーバを仮想化させる作業を(PentiumMで動くキューブPC上で)VMware vCenter converterがしていたということを知ると、少し意外に・面白く感じるかもしれません。
 新サーバは、サイトから得た広告費をすべて投入し組み上げてました。CPUは、PentiumMからCore2Quadに、メモリは2GBから16GBにして、新装開店してみました。
新サーバは、サイトから得た広告費をすべて投入し組み上げてました。CPUは、PentiumMからCore2Quadに、メモリは2GBから16GBにして、新装開店してみました。
そんなわけで、ここに、ひとことお礼を書きたいと思います。おかげさまで、サーバを「新装開店」させることができました。本当に、ありがとうございます。おかげさまで、メモリ不足であきらめることなく、色々なWEBアプリを組んで、チャレンジしてみたりすることができそうです。
2010-03-02[n年前へ]
■ファイル末尾からn行目を高速に読み込むRuby関数
 他アプリケーションが書き出すログファイルを、刻々Rubyで読み・内容に応じた処理をさせたい、と思う状況もままある、と思います。そんな時、ログファイルを逐一読むと時間がかかってしまうので、保存されているログファイルの末尾から2行目だけを読みたくなります。
他アプリケーションが書き出すログファイルを、刻々Rubyで読み・内容に応じた処理をさせたい、と思う状況もままある、と思います。そんな時、ログファイルを逐一読むと時間がかかってしまうので、保存されているログファイルの末尾から2行目だけを読みたくなります。
ファイル末尾からなぜ2行目を読むかというとそれは、ファイル末尾行は書きだし中で、欲しい情報には十分ではない、というような理由です。そこで、Rubyで書いた「ファイル末尾からn行目を高速に読む」関数を、ここにメモしておきます。
この関数"tail"の引数は、
- filename:開きたいファイル
- line:末尾から何行目を出力する(返す)か
- readLength:末尾から何バイト(だけ)を読みこみ、処理させるか ら行目の内容を出力する、という具合です。
def tail(filename,line,readLength)
ary=[]
f=File.open(filename)
begin
f.seek(-readLength,IO::SEEK_END)
rescue
end
while f.gets
ary<<$_
end
f.close
return ary[ary.length-line]
end
while true
puts tail(ARGV[0],1,64)
sleep 1
end
このスクリプトを、tail.rbというような名前で保存し、
ruby tail.rb readme.txtとすれば、その瞬間に保存されているreadme.txtの下から2行目を出力し続ける、ということがされます。
 Rubyで他アプリケーションのログファイルをリアルタイム監視して、何らかの動作・制御を行わせたい・・・という実に「ニッチ」な用途のスクリプトです。しかし、同じようなことをする状況の人も多いかもしれない、というわけで、今日は、ここにメモしておくことにします。
Rubyで他アプリケーションのログファイルをリアルタイム監視して、何らかの動作・制御を行わせたい・・・という実に「ニッチ」な用途のスクリプトです。しかし、同じようなことをする状況の人も多いかもしれない、というわけで、今日は、ここにメモしておくことにします。
2010-03-03[n年前へ]
■「自然の力」と「人間の力」 (初出:2005年09月02日)
 とても華やかな景色を、横にちょっと飾ってみました。この写真は、一昨年のちょうど今頃ニューオーリンズで撮影した写真です。(アメリカの中では有数の)古い街並みが素晴らしく、古い街並みではジャズ(発祥の地ですから)や色んな音楽を演奏している人たちが本当にたくさんいて、とても趣のある素敵な景色でした。一番古い街並みが残っているフレンチ・クオーターには、夜にいつも人が溢れていました。
とても華やかな景色を、横にちょっと飾ってみました。この写真は、一昨年のちょうど今頃ニューオーリンズで撮影した写真です。(アメリカの中では有数の)古い街並みが素晴らしく、古い街並みではジャズ(発祥の地ですから)や色んな音楽を演奏している人たちが本当にたくさんいて、とても趣のある素敵な景色でした。一番古い街並みが残っているフレンチ・クオーターには、夜にいつも人が溢れていました。
 最近、報道でずいぶんと変わり果てているニューオーリンズの街並みを見かけます。右の写真に写っているスーパー・ドームには市民が避難していて、そして、私がこの写真を撮影した(スーパー・ドームの横に立つ)ホテルは外側のガラスが全壊に近いようです。
最近、報道でずいぶんと変わり果てているニューオーリンズの街並みを見かけます。右の写真に写っているスーパー・ドームには市民が避難していて、そして、私がこの写真を撮影した(スーパー・ドームの横に立つ)ホテルは外側のガラスが全壊に近いようです。
テレビの画面には、この写真を撮影した辺りに、周囲から避難してきた市民が溢れているようすが映っていました
 洪水や地震や津波や噴火・・・といったさまざまを起こす自然の力が強いように、弱い人間もやはりそれでも強い、と私は思います。だから、少し時間が経てばニューオーリンズの街も活気を取り戻していくのだろうと信じます。
洪水や地震や津波や噴火・・・といったさまざまを起こす自然の力が強いように、弱い人間もやはりそれでも強い、と私は思います。だから、少し時間が経てばニューオーリンズの街も活気を取り戻していくのだろうと信じます。
そう願いながら、酷い状況の景色だけでなく、とても綺麗だったニューオーリンズの写真を同時に眺めたくなりました。だから、今日はこんな写真を飾ってみました。
一番最後に置いた、右の写真はニューオーリンズの中心、そのフレンチ・クオーターのさらに中心にあるセント・ルイス大聖堂の中で見た景色です。人が祈る、ただそんな姿です。
2010-03-04[n年前へ]
■「過去」と「現在」と「未来」の景色 (初出:2005年09月03日)
![]() 昨日、ニューオーリンズで以前撮影した写真を眺めてみました。ハリケーン"Katrina"「カトリーナ」に襲われたニューオーリンズで、「カトリーナ」に襲われる前の過去に眺めた綺麗な景色を見てみました。
昨日、ニューオーリンズで以前撮影した写真を眺めてみました。ハリケーン"Katrina"「カトリーナ」に襲われたニューオーリンズで、「カトリーナ」に襲われる前の過去に眺めた綺麗な景色を見てみました。
「カトリーナ」の傷跡が復興するまでの長い間、ニューオーリンズの「現在の景色」と「過去の景色」を、Google Mapで眺めることができました。眺めるための機能がつけられていました。
過去の上空から撮影されたニューオーリンズのスーパードームや、あるいは、("Katrina"という赤い部分を押すことで眺められる)崩れ落ちかけたスーパードームのようすを見ることができました。
天井が剥がれおち、ずいぶんと荒れてしまった街が見え、そして、そこからさらに離れた地域は、それよりもっと大変な状態であることもわかりました。
この地図を提供していたGoogleの開発者たちは、被災したニューオーリンズの状況を、その地にいる人たちのことを考え心配している人たちに(あるいはそれ以外の人たちにも)知らせたくて、こんな機能追加を(驚くべき速さで)急遽行ったのでしょう。
 「過去の景色」と「現在の景色」を、眺めいていると、色々なことが見えてくるに違いありません。赤字を背景にした"Katrina"「カトリーナ」という文字から、そんな時間を追って変化する景色が見えてくるような気がします。
「過去の景色」と「現在の景色」を、眺めいていると、色々なことが見えてくるに違いありません。赤字を背景にした"Katrina"「カトリーナ」という文字から、そんな時間を追って変化する景色が見えてくるような気がします。
もちろん、そこからは、過去や現在の先にある復興した未来の姿も見えてくるはずです。
2010-03-05[n年前へ]
■誰でも「必ず」巨乳になるブラのヒミツ!? (初出:2006年03月03日)
 以前、「寄せて上げるブラ」と「飛び出すブラ」に関する記事を書いた際、「今日の必ずトクする一言」のヤマモトさんからこんな提案&質問が寄せられていました。(ちなみに右上の書籍は、「ブラジャー研究家」青山まりの最近の著書です)
以前、「寄せて上げるブラ」と「飛び出すブラ」に関する記事を書いた際、「今日の必ずトクする一言」のヤマモトさんからこんな提案&質問が寄せられていました。(ちなみに右上の書籍は、「ブラジャー研究家」青山まりの最近の著書です)
以前作成したイリュージョンブラですが、光線の影を加えたらどうなるのでしょう? 地上では、必ず上から照らされるものですし(昔から、舞台では山の上側に白いファンデ、谷間にブラウンのファンデを塗るそうです)。
以前からの疑問ですが、hirax.netではブラネタが非常に多い割に、美人ネタでは微乳な仲間さんがでてくるのが疑問です。とすると、あるいは平林さんの脳内には二次元キャラと三次元オブジェクトが葛藤しているのかな?と思った次第です。
 二年ほど前、”乳形状計測デジカメ”による「巨乳ビジョン」を考えた頃、 「グラデーション・セーター」という服(記事)が書かれていました。「グラデーション・セーター」の特徴を一言で言ってしまえば、「(上から光が当たっていることを考慮して)胸の下部にウソっこ陰影を描いている」ということです。
二年ほど前、”乳形状計測デジカメ”による「巨乳ビジョン」を考えた頃、 「グラデーション・セーター」という服(記事)が書かれていました。「グラデーション・セーター」の特徴を一言で言ってしまえば、「(上から光が当たっていることを考慮して)胸の下部にウソっこ陰影を描いている」ということです。
それはまさに、ヤマモトさんがご指摘されているような効果を狙った服ということになります。 実際、物体の凹凸を判断するときには、私たちは物体の陰影情報に頼るものです。その結果、陰影が強くついていれば凹凸が激しい、と私たちは判断します。例えば、下の半球を描いた二枚の画像の立体感を比べれば、右の半球の方が明らかに出っ張って見えるわけです。


そのため、女性は自分の顔をキャンバスとして、偽の陰影を化粧で描くことで鼻を高く見せ、顔の形状をすっきりさせます。
その一方で、男性は(女性の)胸の陰影から胸の大小を判断する(騙される)わけです。ちなみに、そんな「(女性の)胸の陰影から胸の大小を判断する」という現象を科学技術で再現したのが、私が以前作成した「巨乳ビジョンLight」 です。
そういうわけで、ヤマモトさんご指摘の”誰でも巨乳になるイリュージョンブラ”を考える際には、「光線の影を付加」というのは必要不可欠な技術要素だと考えています。
 そういうこともあり、昨年の夏、深夜テレビで「誰でも必ず巨乳になるブラ」 を試作した際には「錯視効果+陰影効果+α」というような合わせ技ブラジャーにしました。それが下のブラジャーの型紙になります。実際に試作してみると、陰影効果による巨乳化現象は無視できないほど効果が大きいことがわかります。どんなことであっても、実際に作ってみなければわからないことが多い、ものなのです。
そういうこともあり、昨年の夏、深夜テレビで「誰でも必ず巨乳になるブラ」 を試作した際には「錯視効果+陰影効果+α」というような合わせ技ブラジャーにしました。それが下のブラジャーの型紙になります。実際に試作してみると、陰影効果による巨乳化現象は無視できないほど効果が大きいことがわかります。どんなことであっても、実際に作ってみなければわからないことが多い、ものなのです。
こういった「錯視効果+陰影効果」デザインは、(あまり人に見せる状況が無い)下着の場合には役に立ちません。しかし、たとえば、ビキニ水着のような場合には、意外に役に立つデザインになるように思います。
というわけで、服飾メーカのみなさま、我がhirax.netはいつでも、こうしたイリュージョン・ブラジャーに関する商品提案をすることができます。また、「見せる技術」だけでなく、「計測・探索」する技術に関しても多くの技術提案をできるかと思います。お役にたてれば、幸いです…!?

2010-03-06[n年前へ]
■WEBサーバを仮想化マシン上に移行させました
 WEBサーバを仮想化マシン上に移行させ始めました。これまで動いていたキューブ・マシンをVMware vCenter Converterで環境コピー&仮想化させた後に、キューブ・マシンをシャットダウンさせ、入れ替わりに(仮想化させたキューブ・マシンを)VMware Player上で動かし始めました。
WEBサーバを仮想化マシン上に移行させ始めました。これまで動いていたキューブ・マシンをVMware vCenter Converterで環境コピー&仮想化させた後に、キューブ・マシンをシャットダウンさせ、入れ替わりに(仮想化させたキューブ・マシンを)VMware Player上で動かし始めました。
現在は、SQLサーバのみネイティブ・マシンで動いていて、アプリケーション・サーバは(そのSQLサーバを動かしているPC上で)仮想化マシンとして動作している、という具合にしています。しかもサクサクッとメンテナンスを行うことができるわけでない私のような素人の方が、長く個人サーバを運用しようとする際には、「仮想化マシン上でサーバを運用する」というやり方は、メリットが多いのではないか、と考えています。
 24時間ほどテスト稼働させてみた際には、VMware Player のネットワーク接続が不安定気味で、たまに接続不能になることがありました。そういう不具合は抱えつつも、サーバ環境は移行させてしまいました。おそらく起きるだろう障害に対しては、順次、対応作業をしていくつもりです。
24時間ほどテスト稼働させてみた際には、VMware Player のネットワーク接続が不安定気味で、たまに接続不能になることがありました。そういう不具合は抱えつつも、サーバ環境は移行させてしまいました。おそらく起きるだろう障害に対しては、順次、対応作業をしていくつもりです。
WEBサーバに関する動作不具合などありましたら(今のところ、初回のリクエストに対してエラーメッセージを返すような挙動が見られます。…とりあえず、そんな時はリロードを一回してみてください)、jun@hirax.netまでご連絡頂ければ幸いです。優先順位が高いものから修正していく予定です。もちろん、第一優先は、httpdが反応しない、というものになります。
2010-03-07[n年前へ]
■「hirax.netサーバ(マシン)売ります」と「トービンのq」
 hirax.netサーバを新サーバ構成に入れ替えた(仮想化PC上で動作させるように替えた)ことに伴い、ここ2年ほどhirax.netの中核を担っていた(しかも、ここ一か月は全てを担っていた)「キューブPC」を廃棄(不燃物として毎週一回の回収日に捨てることができる程度の大きさですから)、ないし、売却しようと思っています。つまり、「hirax.netのサーバ(マシン) for Sale」「hirax.netサーバ(マシン)売ります」ということになります。
hirax.netサーバを新サーバ構成に入れ替えた(仮想化PC上で動作させるように替えた)ことに伴い、ここ2年ほどhirax.netの中核を担っていた(しかも、ここ一か月は全てを担っていた)「キューブPC」を廃棄(不燃物として毎週一回の回収日に捨てることができる程度の大きさですから)、ないし、売却しようと思っています。つまり、「hirax.netのサーバ(マシン) for Sale」「hirax.netサーバ(マシン)売ります」ということになります。
この「キューブPC」は、小型のキューブタイプの"WINDY TIPO"というベアボーンPCで、Pentium 4 2.4GHz、2GB RAMの300GB HDというスペックです。ハードディスクの中身には、hirax.netで稼働させていた各種WEBアプリケーション(ソース)、および、そこから呼び出していた連携用(各種言語による)自作ライブラリ・アプリケーションなどが全て含まれています。
それだけなら良いのですが、このPCには、アクセスログなども含まれています。さらに、ファッション雑誌WEBアプリではアクセス元の都市解析と流行分布解析、なども行っていましたし、顔処理画像処理アプリでは、抽出顔画像からの年齢解析・顔中の色分布解析・地域ごとの化粧方法の差異解析・顔タイプ情報の蓄積・嗜好解析等をバックエンドで行っていました。つまり、破棄ないし売却する前に、完全に破棄しなければいけないデータも含まれているのです(ある期間より過去のデータに関しては、すでに、全て削除しています)。
![]() WEBアプリケーションのソースは、(ハードウェアを売るなら)オマケにつけても良いかななどとは思いますが、(データ抹消ミスをしないためには)ハードディスクをひとまず完全消去してしまうのが、私の手間は一番手間が少なくて済みそうです。また、Pentium 4 2.4GHz、2GB RAMの300GB HDという程度のスペックのPCでは、普通に動くような状態でも、買いたいという人が現われるかどうかすら怪しいような気がします。ましてや、電源を入れると、いきなり各種WEBサーバーが起動してしまうような状態では、買い手が現れるとは思えません。
WEBアプリケーションのソースは、(ハードウェアを売るなら)オマケにつけても良いかななどとは思いますが、(データ抹消ミスをしないためには)ハードディスクをひとまず完全消去してしまうのが、私の手間は一番手間が少なくて済みそうです。また、Pentium 4 2.4GHz、2GB RAMの300GB HDという程度のスペックのPCでは、普通に動くような状態でも、買いたいという人が現われるかどうかすら怪しいような気がします。ましてや、電源を入れると、いきなり各種WEBサーバーが起動してしまうような状態では、買い手が現れるとは思えません。
そんなことを考えているうちに、ふと「トービンのq」を思い出しました。
ジェームズ・トービンという金融経済学者が主張した”トービンのq”っていう理論があります。トービンのqというのは、すごく単純な分数で、分母が「その会社とまるまる同じものを、もうひとつ作るのにいくらかかるかという再取得費用」で、分子が「株を全部買い占めるためにいくらかかるかという株価総額」というものです。

この分数qの値は、1より大きいのが原則なんです。つまり下部を全部買い占めてその会社を手に入れるほうが、単にハコモノを作るよりも、ずっとお金がかかるということです。
小島寛之@「理系サラリーマン 専門家11人に「経済学」を聞く!」 (参考書評)
なるほど、「PC売値/パーツ代総額」が1を下回ることなんて、あり得ないですものね。hirax.netのサーバ・マシンの場合、意外なことに、ハードディスクやメモリをバラして売ってしまった方が(ソフト部分には値段がつかないでしょうし)、高額になるような気がします。そうすれば、メモリ代金だけでも数千円程度にはなるように思います。しかし、一括で売ろうとすると、買い手すら現れないような気もするのです。売り手からすれば、「あり得ない状態」ですが、「買い手」からすれば「要らないものは要らない」わけですから、しょうがありません。
これは、まさに「トービンのq」が1を切っている状態です。PCパーツ代・それらを組み合わせたPC上で動くシステムトータルでは買い手が現れず売買が成立しないのにも関わらず、サーバ・システムを「切り売り」すれば値段がつき、全体よりも高い価格になる…という状況です。
建物とか設備とか機械とかを全部そろえて、さらに、同じような能力の人間を雇ったとしても、(中略)働く人たちの間で共有された情報や蓄積された経験、あるいは、築いた信頼関係と言った「企業のなかにあるプラスアルファの価値」が株価に反映されているわけです。
小島寛之
目には映りにくい「働く人の間のつながりといった社会的な価値あるもの」も、高い株価というカタチできちんとその価値が目に見えるモノにされているんだ、と実感してきました。徒然なるままに、ノートPCに向かい、心に浮かんだことをそこはかとなく書いてみました。、「hirax.netサーバ(マシン)」は「トービンのq」が1以下の状態でそのまま売るか、バラして「切り売り」するか、どうするかを考えているところです。
2010-03-08[n年前へ]
■仕事仲間との「給料の比率」 (初出:2006年03月21日)
「(漫才の)ネタを書く側をSE、そうでない人をプログラマとして、人気コンビに例えて、ギャラ比率をレポート(考えよう)」という記事を読んだことがあります。仕事を一緒にする人、けれど仕事の内容は違う人の間では、一体どんな割合でギャラを分けているものなのだろうか?というレポートです。その記事を読んだとき、ウォームビズに関する計算を行い、そして記事を書いた時のことを思い出しました。
「何だか大変な仕事になってしまいましたねぇ…」
「この仕事量だと、いくらぐらいの報酬をもらいたいと思いますか?」
「あと、私たち二人(編集者の方と私)の間で、ギャラの分け前は一体どんな感じだったら納得します?」
その後、「(ギャラの分け前は)半々でいいんじゃないでしょうか? たいていの場合は、下っ端エンジニアの方が”しきり役”より報酬って安いですけどね」と私が書けば、つまり、「いいんじゃないでしょうか」と言いながら…半分寄こせと要求する私に対し、「いやいや、ふつう、選手の方が監督より年俸は高いでしょう?それに、こういった業界では、筆者の方がしきり役(編集者)よりギャラが安いということはありえないんです…」と、大人の編集者は淡々と書かれたりするのです。
 異なる仕事をする人の間で、「報酬の分け前がどんな感じだったら納得できるか?」というのは難しい問題であるように思えます。基本的に、長く仕事を一緒にしたい人との間では、難しいことは考えず等分にするのが一番気持ち良いような気がします。二人なら半分に、三人なら三等分に・・・というのが、心地良いように思います。
異なる仕事をする人の間で、「報酬の分け前がどんな感じだったら納得できるか?」というのは難しい問題であるように思えます。基本的に、長く仕事を一緒にしたい人との間では、難しいことは考えず等分にするのが一番気持ち良いような気がします。二人なら半分に、三人なら三等分に・・・というのが、心地良いように思います。
こんな時、なんだか難しいことを考えようとする時には、経済学者 石川経夫の言葉を、今一度眺め直してみることにしましょうか。
この世は不公平なものだが、
それぞれが努力すればそれに見合ったものを
みんなが得られるようになる社会を
どうすれば実現できるだろう、
ということを愚直なまでに考えるのが経済学だ。
2010-03-09[n年前へ]
■「電子ペーパー」でもあるエクセルは、プロトタイピングに向いている。
 オライリーの「Excelプロトタイピング ―表計算ソフトで共有するデザインコンセプト・設計・アイデア
オライリーの「Excelプロトタイピング ―表計算ソフトで共有するデザインコンセプト・設計・アイデア
」を読みました。この本は、Excelを代表とする表計算(スプレッド・シート)ソフトで、アプリケーションやWEBページの「見た目」や「大まかな動作」の試作品(プロトタイプ)を簡単に作る方法を解説したものです。一番最初は、「えっ?これがオライリーの本!?」と驚くくらい、カラーページが多く、画面キャプチャをふんだんに使いつつ「やり方の説明」が書かれている本です。
「エクセル=時間泥棒」という等式が成り立つ、と私は感じています。ただし、この等式が成立するのはある条件下においてであるとも思っています。その条件とは、「定型的な作業で、とても簡単に自動化できることのはずなのに、それを人が繰り返し似たような作業を時間をかけて行っている場合」「(エクセルでない)違う道具を使えば、簡単に(作成した)道具の再利用が可能になるだろう場合」というものです。
そういった場合でないならば、たとえば、「一回こっきりの作業」や「一番最初のアイデアスケッチ」をするような時であるならば、エクセルを使うのは悪くない選択肢だと思っています。だから、「(とっても簡単な)プロトタイピング」であれば、Excelを使って「やってみる」こともあります。
![]() エクセルは、良くも悪くも、まさに「見たまま」に作業をすることができます。その「特徴」は、「(非常に簡単な)プロトタイピング」をする時には、「特長」すなわち長所になります。ところが、複雑なものを作ろうとする場合になると、その特徴はまさに短所になってしまうのです。たとえば、画面内にとても収まらないような巨大なスプレッド・シートを作る羽目(はめ)になってしまったりします。
エクセルは、良くも悪くも、まさに「見たまま」に作業をすることができます。その「特徴」は、「(非常に簡単な)プロトタイピング」をする時には、「特長」すなわち長所になります。ところが、複雑なものを作ろうとする場合になると、その特徴はまさに短所になってしまうのです。たとえば、画面内にとても収まらないような巨大なスプレッド・シートを作る羽目(はめ)になってしまったりします。
あくまで、比較的簡単で小さなものを作るという条件下において、見た目そのままに思いつくままに作業することができるエクセルは、なかなか現実的な「プロトタイピング開発環境」になると感じているです。
 私は、エクセルは「電子ペーパー」だと思っています。もともと、紙上で行っていた集計作業を楽にするために作られたのが表計算ソフト(VisiCalc)であって、エクセルはその流れから生まれたものです。「プロトタイピング」という作業には、一番「紙=ペーパー」が最適だと(より正確にいえば、ホワイトボード+記録媒体という組み合わせが一番良いと思っています)、旧ザクならぬ旧世代の私は思っています。だから…というのも変ですが、「電子(処理機能を備えた)ペーパー」でもあるエクセルは、プロトタイピングに向いているように感じられます。
私は、エクセルは「電子ペーパー」だと思っています。もともと、紙上で行っていた集計作業を楽にするために作られたのが表計算ソフト(VisiCalc)であって、エクセルはその流れから生まれたものです。「プロトタイピング」という作業には、一番「紙=ペーパー」が最適だと(より正確にいえば、ホワイトボード+記録媒体という組み合わせが一番良いと思っています)、旧ザクならぬ旧世代の私は思っています。だから…というのも変ですが、「電子(処理機能を備えた)ペーパー」でもあるエクセルは、プロトタイピングに向いているように感じられます。
 ところで、本書のタイトル「Excelプロトタイピング」には、「やられた」と思いました。なぜなら、私が編集者だったとしたら、そういうタイトルの(シリーズ)本を作ってみたいと思っていたからです。「Excelでプロトタイピング~○×編~」という本をいくつか、編集者として作ってみたかったのです。そして、自分自身、そこから学んでみたかったのです。
ところで、本書のタイトル「Excelプロトタイピング」には、「やられた」と思いました。なぜなら、私が編集者だったとしたら、そういうタイトルの(シリーズ)本を作ってみたいと思っていたからです。「Excelでプロトタイピング~○×編~」という本をいくつか、編集者として作ってみたかったのです。そして、自分自身、そこから学んでみたかったのです。
その思いは、たぶん自動的に下に出てくるだろう、この記事の「関連お勧め記事」を読む、を眺めればわかるだろうと思います。
2010-03-10[n年前へ]
■『脳の本』はどんな人が読んでいるのか?
![]() 脳科学に関する本がたくさん出版されている。そんなたくさんの本のことを考えてみよう、という本が出た。それが、森 健「脳にいい本だけを読みなさい!― 「脳の本」数千冊の結論 (Kobunsha Business)
脳科学に関する本がたくさん出版されている。そんなたくさんの本のことを考えてみよう、という本が出た。それが、森 健「脳にいい本だけを読みなさい!― 「脳の本」数千冊の結論 (Kobunsha Business)
」だ。
「そもそも、なぜこんなに多くの『脳の本』が出ているのか」
「これら『脳の本』はどのような中身なのか」
「これら『脳の本』はどんな人が書いているのか」
以前、ある記事群を書いていたとき、担当編集者に何度も何度も同じことを、「読者はどういう人たちなのでしょうか?」ということを、繰り返し尋ねた。繰り返し私が同じ疑問を尋ねたその人から、森健さんが「脳科学に関する本」をまとめた本を書いている、という話を聞いた。
実際に会ったことがある人の本は、なぜか、ネット注文する気分になれない。だから、時間をかけて本屋に行って、その本を手にとって買うことにしている。
 森健さんには、確か池袋の喫茶店で会ったことがある。だから、この本は何軒もの本屋を訪ね歩き、そして買って読んだ。気付いてみれば、普通に目立つところに平積みにされていたのだけれど、「脳」という言葉から連想する棚、「○×しなさい」という言葉から連想する本棚、茂木健一郎と勝間和代の本がズラリと並ぶ棚の中から一冊の本探しをするという作業は、何だかアマゾンの奥地を彷徨(さまよ)っているような感じがして、とても疲れる作業に感じられた。
森健さんには、確か池袋の喫茶店で会ったことがある。だから、この本は何軒もの本屋を訪ね歩き、そして買って読んだ。気付いてみれば、普通に目立つところに平積みにされていたのだけれど、「脳」という言葉から連想する棚、「○×しなさい」という言葉から連想する本棚、茂木健一郎と勝間和代の本がズラリと並ぶ棚の中から一冊の本探しをするという作業は、何だかアマゾンの奥地を彷徨(さまよ)っているような感じがして、とても疲れる作業に感じられた。
私は、「そもそも、なぜこんなに多くの『脳の本』が出ているのか」にはとても興味がある。なぜかというと、平積みにされている『脳の本』には、私自身はまったくと言ってよいほど興味がないからだ。平積みにされていない『脳の本』には興味があるのだが、不思議なほどに、平積みにされている『脳の本』には興味を惹かれない。
そして、当然のごとく、「これら『脳の本』はどのような中身なのか」ということにも、「これら『脳の本』はどんな人が書いているのか」ということにも興味がない。つまり、私は「脳にいい本だけを読みなさい!」というタイトルの本に対しては100%の良い読者ではない。むしろ、100%悪い読者である。けれど、だからこそ、「そもそも、なぜこんなに多くの『脳の本』が出ているのか」にはとても興味があるのだ。なぜなら、それこそが私の知らない・わからない世界だからだ。
さらに、森健さんが、上記3つの疑問から導くさらなる2つの疑問のうちの片方は、私も心底知りたいものだった。
「これら『脳の本』はどんな人が読んでいるのか」一番目の、「これら『脳の本』はどんな人が読んでいるのか」ということには、とても興味がある。それは、まさに私が知りたいことだ。私が知りたいのは、本の作者でも内容でもなく、その本を読む読者の姿、だ。
「これら『脳の本』の中身は科学的な内容が担保されたものか」
ただし、2番目の「これら『脳の本』の中身は科学的な内容が担保されたものか」という疑問は、私の興味外のことである。平積みにされている『脳の本』自体に、興味がなく、その内容についても興味がないから、である。しかし、だからこそ、そうは思わないたくさんの読者のことは知りたいと思う。そういうわけで、「これら『脳の本』はどんな人が読んでいるのか」ということの手掛かりを得たい・知りたいと思いつつ、この本を読んだ。
…この本を読んだ限りでは、「これら『脳の本』はどんな人が読んでいるのか」ということについては私にはよくわからなかった。私には、その疑問への答えは読み取れなかった。しかし、他の人には読み取れるかもしれない。だから、その疑問の答えがわかる・感じる人がいたならば、ほんのカケラでもいいから、そのヒントを教えて欲しいと思う。
この本に書かれているのは、「これら『脳の本』はどのような中身なのか」「これら『脳の本』はどんな人が書いているのか」という2点に尽きる。つまり、全部で5つの質問のうちの2つである。5つの疑問のうちの最後の疑問、「これら『脳の本』の中身は科学的な内容が担保されたものか」という疑問の答えは書いてあるような、書いてないような、けれどそのとちらでも私にはどうでもよいことだ。これら『脳の本』に関する作者にも、内容にも、私の興味はないからだ。
森健さんが差し出した「残りの2つの疑問」、「そもそも、なぜこんなに多くの『脳の本』が出ているのか」「これら『脳の本』はどんな人が読んでいるのか」という疑問に対する、森健さんなりの言葉を読みたいと思う。
2010-03-11[n年前へ]
■各種Rubyを切り替えるpikを使ってみる
 いくつかの異なるバージョンのRubyをインストールし、自由に切り替えて使うことができる、しかもgemでのアップデートなども同時に行うことができるpikを使い始めました。使い始めた理由は、好きな時に好きな「Rubyのバージョン違い・IronRubyやJRubyといった異なるRuby」を使ってみたかったからです。
いくつかの異なるバージョンのRubyをインストールし、自由に切り替えて使うことができる、しかもgemでのアップデートなども同時に行うことができるpikを使い始めました。使い始めた理由は、好きな時に好きな「Rubyのバージョン違い・IronRubyやJRubyといった異なるRuby」を使ってみたかったからです。
まず、gemでインストールします。つまり、最初にRubyが入っていることが前提です。そして、その時に入っていたRubyが「default」になります。
gem install pikすると、使い方の説明表示とともに、インストールが終わります。
 さらに、pikの配置作業を行いましょう。適当な場所にインストールして(環境変数の)PATHに追加するか、最初からパスが通っている(PATHに入っている)ディレクトリにpikを配置します。ここでは、単純のために、"C:\Windows"にpikを配置してみます。
さらに、pikの配置作業を行いましょう。適当な場所にインストールして(環境変数の)PATHに追加するか、最初からパスが通っている(PATHに入っている)ディレクトリにpikを配置します。ここでは、単純のために、"C:\Windows"にpikを配置してみます。
pik_install C:\Windows
次は、さまざまなRubyのインストールです。pikでは、インストールできるRubyが自動でわかります。そこで、このようなコマンドを打ちます。
pik ls -r -Vすると、
pik 0.2.6 --- IronRuby: (以下省略) JRuby: (以下省略) Ruby: (以下省略)といった風に、インストールできるRuby一覧が出てきます(後で書くように、手動でこれ以外のRubyもインストールできます)。
適当なRubyをインストールするには、たとえば、このようにします。
pik install rubyすると、自動でRubyの一番新しいバージョンの 1.9.1-p378: http://rubyforge.org/frs/download.php/69039/ruby-1.9.1-p378-i386-mingw32.7z がインストールされます。
pik install jruby
pik install ironrubyでも同じです。また、もしもRubyのバージョン指定でインストール作業を行いたいならば、指定方法は色々ありますが、たとえば、
pik install ruby -v 1.8.7という具合です。
また、自動ではリストアップされないものに関しては(今日現在でのIronRubyの最新版1.05c=0.9.4などは自動ではリストアップされません)、手動で、ローカルにインストールした上で、
pik add C:\Windows\pik\IronRuby-094\binとしてやれば、gemの管理下に入ります。
あとは、
pik listと打てば、
092: IronRuby 0.9.2.0 on .NET 094: IronRuby 0.9.4.0 on .NET 140: jruby 1.4.0 186: ruby 1.8.6 [i386-mswin32] * 187: ruby 1.8.7 191: ruby 1.9.1p378という風に、切り替えて使うことができるRuby一覧が出てきます。あとは、
pik switch 191とすれば、ruby 1.9.1p378 (2010-01-10 revision 26273) [i386-mingw32]が使われるように切り替わります。別に191という指定でなくても、「191: ruby 1.9.1p378 (2010-01-10 revision 26273) [i386-mingw32]」という文字列の中から他と区別できる文字列をswitchで指定してやれば良いようになっています。
基本的には、「パスを切り替える」という作業を行うものなので、この状態で
pik switch 94とIronRuby 0.9.4.0に切り替えて、
ruby -vと打っても、こう言われるだけです。
'ruby' は、内部コマンドまたは外部コマンド、 操作可能なプログラムまたはバッチ ファイルとして認識されていません。この場合は、
ir.exe -vとするか、そもそも(Ironrubyの)ir.exeをruby.exeという名前に変えておく必要があります。
pikを使うと、Rubyを切り替えることができるのも便利ですが、各Rubyにgemを一括で行うことができるのも便利です。たとえば、
pik gem install win32-mmap
 とすれば、各Rubyに切り替えつつ、それぞれに対してgemを行ってくれます。ただし、Rubyを切り替えた場合には、そのRubyの機能内のことしかできなくなる、ということには注意が必要です。IronRubyに切り替えたときなどは、実装されていないメソッドによりpik自体も、手作業なしに完全に自動で終了する、といわけではなかったりします(といっても、pikを使った方がずっと便利です)。どうしても、困ったことが起きた瞬間には、
とすれば、各Rubyに切り替えつつ、それぞれに対してgemを行ってくれます。ただし、Rubyを切り替えた場合には、そのRubyの機能内のことしかできなくなる、ということには注意が必要です。IronRubyに切り替えたときなどは、実装されていないメソッドによりpik自体も、手作業なしに完全に自動で終了する、といわけではなかったりします(といっても、pikを使った方がずっと便利です)。どうしても、困ったことが起きた瞬間には、
pik defaultとして、「default」のRubyに戻して、作業をしてみましょう。
2010-03-12[n年前へ]
■「胸のドキドキ」がわかるブラジャー (初出:2005年12月31日)
 今月初旬、心拍計付きブラジャー NuMetrex™ Heart Rate Monitoring Sports Bra が発表され、ニュースになっていました。女性が心拍計を胸に取り付けてもほとんど負担に感じない、という商品です。といっても、こういった心拍計を胸に当てることができるブラジャー型サポーターというのは以前からありました。例えば、PolarのHeartBeat Braなどもある(販売サイト例)のようなものがありました。
今月初旬、心拍計付きブラジャー NuMetrex™ Heart Rate Monitoring Sports Bra が発表され、ニュースになっていました。女性が心拍計を胸に取り付けてもほとんど負担に感じない、という商品です。といっても、こういった心拍計を胸に当てることができるブラジャー型サポーターというのは以前からありました。例えば、PolarのHeartBeat Braなどもある(販売サイト例)のようなものがありました。
通常、スポーツ用の心拍計は胸にベルト状のものを巻いて取り付けます。私にはわかりませんが、女性の場合、やはり胸に取り付けるのには形状的に無理があるのかもしれません。あるいは、胸の表面から心臓まで(男性よりも少し)遠い分、センサーを巻き付ける圧力が高くなってしまったりして、負担に感じやすかったりするのでしょうか…。
ところで、こういうブラを眺めていると、やはりデート中のカップルに着用してみてもらいたくなります。隣り合って食事をしたり、二人手をつないでいたり…とそんなことをしているカップルの心拍数を、それぞれ独立に眺めてみたくなります。「あれ?男性の方は胸がドキドキしてるのに、女性の方は心拍数が低いぞ…。これは、平常心そのものだぁ!?」とか、「女性はドキドキしてるのに、男性はやたら冷めてるぞ…」といったことが、わかったりするかもしれません。
そんな「胸のドキドキ」がわかるブラジャーを買ってデート時に使ってみたい、という女性はいないものでしょうか。といっても、いないですよねぇ、やっぱり…。
2010-03-13[n年前へ]
■「時間と場所をわきまえた(TPO)」予測(日本語)変換入力システム (初出:2005年11月01日)
 下の記事を書いたのは、もう5年近く前のことになります。この記事を書いた時には、1,2年もしないうちに、文字入力システムは、この記事で書いたような”「時間と場所をわきまえた(TPO)」予測変換入力システム”になっているだろう、と思っていました。しかし、現実には、そういう製品を未だ見かけていないのが、私には少し解せません。そういう未来にならなかった理由は、文字入力に必用な速度を実現できないと言った実装上の、問題なのでしょうか。それとも、そもそもそういったニーズがない、というようなことだったのでしょうか・・・それとも、こういう考え方がそもそも間違っていたのでしょうか。
下の記事を書いたのは、もう5年近く前のことになります。この記事を書いた時には、1,2年もしないうちに、文字入力システムは、この記事で書いたような”「時間と場所をわきまえた(TPO)」予測変換入力システム”になっているだろう、と思っていました。しかし、現実には、そういう製品を未だ見かけていないのが、私には少し解せません。そういう未来にならなかった理由は、文字入力に必用な速度を実現できないと言った実装上の、問題なのでしょうか。それとも、そもそもそういったニーズがない、というようなことだったのでしょうか・・・それとも、こういう考え方がそもそも間違っていたのでしょうか。
 先月、独立行政法人産業技術総合研究所の増井俊之氏が「携帯端末での文字入力インタフェースの POBox(Predictive Operation Based On eXample)」で第4回ドコモ・モバイル・サイエンス賞」先端技術部門 優秀賞を受賞した。 POBox のようなシステムは、過去に入力した単語・文字の繋がりから、次に入力する文を自動で予測・表示・入力してくれる。つまり、POBoxのようなシステムは「(他の誰でもなく)そのユーザ自身の過去の動作」にもとづいて、「現在・未来に入力する文章を予測」するわけだ。
先月、独立行政法人産業技術総合研究所の増井俊之氏が「携帯端末での文字入力インタフェースの POBox(Predictive Operation Based On eXample)」で第4回ドコモ・モバイル・サイエンス賞」先端技術部門 優秀賞を受賞した。 POBox のようなシステムは、過去に入力した単語・文字の繋がりから、次に入力する文を自動で予測・表示・入力してくれる。つまり、POBoxのようなシステムは「(他の誰でもなく)そのユーザ自身の過去の動作」にもとづいて、「現在・未来に入力する文章を予測」するわけだ。
類似の文字入力システムは、私の携帯電話にも搭載されており、私もとても重宝している。例えば、私の携帯電話では「も」という文字を入力しただけで、「申し訳ありません」と出てくる。もちろん、「ま」という文字ならば、「誠に申し訳ありません」である。あるいは、それが「い」ならば、「今から送付いたします」である。その「過去に入力した単語・文字の繋がりが謝罪ばかり」という点は実に情けない話のだが、その予測文字を毎回使うというところもさらに情けない。 つまりは、あまりにワンパターンの動作を私はいつもしているわけだ。
先日、増井氏の「携帯から位置情報を利用」というUNIX MAGAZINEの記事(PDF)に影響されて、自分用に「 (au)携帯電話GPSス位置追跡ページ」を作った。そして、自分が「いつ」「どの場所にいるか」のデータベースを作り始めた。作った理由はいろいろあるのだが、その一つが携帯電話の文字入力をもっと楽にするために、自分用に(自分の時間やいろ場所やその瞬間に書いたメールを把握することで)「時間と場所をわきまえた(TPO)」予測(日本語)変換入力システムを作りたかったのである。時と場所に応じて、書く文章というのは違うのだから、それを考慮した予測(日本語)変換システム(TPO式POBox = TPOBox)が欲しかった、ということである。
![]() たとえば、8:00 A.M に「お」と私が入力したら、たいていの場合次に続く文字は「おはようございます。」である。そして、9:00 A.M ~7:00 P.M.の間は「遅れて申し訳ありません。」が多い。7:00 P.M.過ぎは「お疲れ様です」という感じだ。つまり、メールを書く時間によって、同じ文字から始まっても「違う文章」を書くことが多い。つまり、(同じ私という人間であっても)それほど「ワンパターン」ではないのである。
たとえば、8:00 A.M に「お」と私が入力したら、たいていの場合次に続く文字は「おはようございます。」である。そして、9:00 A.M ~7:00 P.M.の間は「遅れて申し訳ありません。」が多い。7:00 P.M.過ぎは「お疲れ様です」という感じだ。つまり、メールを書く時間によって、同じ文字から始まっても「違う文章」を書くことが多い。つまり、(同じ私という人間であっても)それほど「ワンパターン」ではないのである。
そして、それは場所によっても同じだ。例えば、平日の9:00 A.M.に品川近辺にいる場合、それは打ち合わせ場所に向かう状況が多いので、「い」という文字を入力した場合に次に続く文章は「今、品川におりますので、あと30分ほどで到着します。」という感じのものが多い。そして、それが平日の8:00 A.M.に東京近辺にいる場合には、違う出張先へ行く場合が多いので、「今、東京に着きました。そちらには9:45に到着予定です。」という感じが多い。つまり、時間と場所によって、入力する内容が自動的に決まる、入力する内容は時間や場所に依存しているのが普通だと思う。
![]() 先ほど、「(他の誰でもなく)そのユーザ自身の過去の動作」と書いたが、「同じユーザであっても違う時間にいるなら、それは違うユーザと考えた方が良いこともあるし、(その同じユーザが)違う場所にいればそれも違うユーザと捉えた方が(そして違う文字を予測した方が)良いこともある」ということだ。そして、そんな「時間と場所に応じたユーザの過去の行い」を学習し、「時間と場所をわきまえた(TPO)」予測(日本語)変換入力システムが携帯電話に搭載されたあかつきには、きっと入力がとても楽になるに違いない、と想像している。つまりは、それは「TPOも考えるならば、すごくワンパターンの行い・繰り返しをユーザがしている可能性が高い」という、現実を示すことになってしまうのだが…。
先ほど、「(他の誰でもなく)そのユーザ自身の過去の動作」と書いたが、「同じユーザであっても違う時間にいるなら、それは違うユーザと考えた方が良いこともあるし、(その同じユーザが)違う場所にいればそれも違うユーザと捉えた方が(そして違う文字を予測した方が)良いこともある」ということだ。そして、そんな「時間と場所に応じたユーザの過去の行い」を学習し、「時間と場所をわきまえた(TPO)」予測(日本語)変換入力システムが携帯電話に搭載されたあかつきには、きっと入力がとても楽になるに違いない、と想像している。つまりは、それは「TPOも考えるならば、すごくワンパターンの行い・繰り返しをユーザがしている可能性が高い」という、現実を示すことになってしまうのだが…。
2010-03-14[n年前へ]
■「フラグメント(アンカー)をhttpサーバーに伝えさせる方法」
 URLとURIは何が違うの? どちらが正しい呼び方?を読んでいると、「とても知りたいこと」がでてきました。それは、「URLの#以降の部分、つまり、アンカー(フラグメント)をhttpサーバで知る方法」です。記事中のアンカー(フラグメント)説明部分には、こうあります。
URLとURIは何が違うの? どちらが正しい呼び方?を読んでいると、「とても知りたいこと」がでてきました。それは、「URLの#以降の部分、つまり、アンカー(フラグメント)をhttpサーバで知る方法」です。記事中のアンカー(フラグメント)説明部分には、こうあります。
フラグメント(fragment)。 アンカーと呼ばれますが、正式にはフラグメント。主となる内容に加えて部分や代替表現を指定します。httpではこの情報は通常はサーバーには伝えられず、サーバーから送られた情報をクライアント(ブラウザ)が処理する際に使います。「httpではこの情報は通常はサーバーには伝えられず」ということは、通常でなければ、サーバーに伝えさせる方法がある、ということでしょうか。そんな風に読めます。
サーバ側で、アンカー(フラグメント)をブラウザ側で(Javascriptなどで)処理するのではなく、アンカー(フラグメント)部分の情報を使ってHTMLを吐き出したいと思うことがあります。けれど、アンカー情報はサーバ側では取得できないから…と諦めていました。
どなたか、「フラグメント/アンカーをサーバーに伝えさせる方法」をご存知でしたら、お教え頂ければ幸いです。
ここから下は、この記事を読んだ方から頂いたアドバイスです。
- URLをまるごとエンコーディングすればサーバに届きます
2010-03-15[n年前へ]
■あみだくじシミュレーションをエクセルでプロトタイピングしてみよう
![]() 「電子ペーパー」でもあるエクセルは、プロトタイピングに向いている。と書いたので、今日は「あみだくじシミュレーション」をExcelで適当に書いて(描いて)みました。そうでした、私は自分自身で作ることが好きなのでした。
「電子ペーパー」でもあるエクセルは、プロトタイピングに向いている。と書いたので、今日は「あみだくじシミュレーション」をExcelで適当に書いて(描いて)みました。そうでした、私は自分自身で作ることが好きなのでした。
作成したエクセルのファイルは、ここに置いておきます。ワークシートの説明(あるいは修正)や、ワークシートを使って色々なことを考えてみよう、ということは明日以降にしてみようと思います。とりあえず、このエクセルのワークシートを実行しているところを動画キャプチャしたものが、下の動画です。
このエクセル・ワークシートは、循環参照を使い、また計算順序を考慮したバッファリングを使うことで計算が成り立っています。ただし、エクセルの実装の仕組みのために、手動計算を行うためにF9を押しっぱなしにしても、反復計算が全セルに渡って行われるわけではないように思えます(これは検証していない未確認情報です)。そのため、計算を確実に行わせようと思うなら、今のところ、(あみだくじの横棒の数だけ)F9を連打する必要があります。
 あみだくじを考えるなら群論を使えとか、IF関数を使うのであればVBAを使うやり方と大して変わらないのでは?とか、エクセルでない他のプログラミング言語を使った方がよっぽど楽にプロトタイピングをすることができるのに…!?という感想も多々出てくるだろうと思います。
あみだくじを考えるなら群論を使えとか、IF関数を使うのであればVBAを使うやり方と大して変わらないのでは?とか、エクセルでない他のプログラミング言語を使った方がよっぽど楽にプロトタイピングをすることができるのに…!?という感想も多々出てくるだろうと思います。
とはいえ、今日はとりあえず、あみだくじシミュレーションをエクセルでプロトタイピングしてみました。(加減乗除だけで実現したのではない)つまらない実装ですが、(あくまで)暇なときに眺めて遊んで頂ければ、幸いです。
2010-03-16[n年前へ]
■説明の文章は「女の子のミニスカート」 (初出:2005年09月05日)
 昨日は、産総研 秋葉原サイトで場所を借りて、「プレゼンについて考える」場に行って少し話をしてきました。「少し話をしてきた」といっても四時間ほどだったので、(聴く側にとってみれば)実際のところはかなりの長丁場だったかもしれません。
昨日は、産総研 秋葉原サイトで場所を借りて、「プレゼンについて考える」場に行って少し話をしてきました。「少し話をしてきた」といっても四時間ほどだったので、(聴く側にとってみれば)実際のところはかなりの長丁場だったかもしれません。
その時に使ったスライドの一つを、右に貼り付けてみました。このスライドに書かれている文章は、"Sentence length is like a girl's skirt: the shorter the better, but it should cover the most important parts."というミシガン・メソッド(ミシガン大学で開発された言語教習の流儀)からひろまったと伝えられている名言です。 日本語に訳すと、「 文の長さは女性のミニ・スカートのようなもので、短ければ短いほど良い。しかし、最も大切な部分はカバーしていなければならない」ということになります。素晴らしく的確な言葉です。
 どうしても、何かを説明する文章を書くときには、だらだらと長く文章を続けてしまう「昔の不良少女スカート」スタイルや、(それとは逆に)短すぎて意味が伝わらない「パンツまる見え超ミニ・スカート」スタイルになりがちです。
どうしても、何かを説明する文章を書くときには、だらだらと長く文章を続けてしまう「昔の不良少女スカート」スタイルや、(それとは逆に)短すぎて意味が伝わらない「パンツまる見え超ミニ・スカート」スタイルになりがちです。
そんな時は、「文(章)の長さはミニ・スカート」とつぶやきながら文章を書いてみると良いかもしれません。そうすれば、きっと、良い説明文章がかけるようになるはずです。 そのブツブツつぶやく内容を聞かれてしまったならば、周りの人には、「かなりアブナイ人」に見えてしまうかもしれませんが…。

2010-03-17[n年前へ]
■「生まれ変わる自分」と「付き合う相手」と「理系と文系」
 「理系と文系」といった分類については、多くの人が一度は考えてみることがある話だと思っていますし、あるいは、一度は考えなければいけない時期があるのかもしれないとも、思っています。さらには、そんな二択の選択肢のどちらかを、選ばなければいけないように見えるときも、あるのかもしれません。
「理系と文系」といった分類については、多くの人が一度は考えてみることがある話だと思っていますし、あるいは、一度は考えなければいけない時期があるのかもしれないとも、思っています。さらには、そんな二択の選択肢のどちらかを、選ばなければいけないように見えるときも、あるのかもしれません。
とはいえ、多くの人は、そういう話題・時期からは離れ・いつの間にか卒業していくものだとも、思っています。それでも、たまには、そんな話題を思い出し考えることもあります。
「理系女子向けのコミュニティ雑誌」を手に取り読んでいると、「生まれ変わるなら、理系と文系のどちらを選ぶか?」「付き合う相手は、理系と文系のどちらが良いか?」を男性・女性/理系・文系の計4種類の人たちに聞いたアンケート結果がありました。そのアンケート結果が、とても興味深いものだったので、その記事を撮影してみました。それが、下のスナップ写真です。

このアンケート結果を眺めたとき、そこから見えてくるのは、理系と文系という二者選択が仮にあったとするのなら、そしてそこに自分の好みというものがないのだったとするならば、文系を選んだ方が良さそうだということです。”いわゆる”理系と文系の男女比率がどのようなものであるかに寄りますが、そのような「答え」が自然に思われます。
この話は、忘れなければ、もう少し続けようと思います。もちろん、適当に、時間をおいつつ、になるとは思いますが…。

2010-03-18[n年前へ]
■男女別「理系・文系 比率」を出してみよう
 「「生まれ変わる自分」と「付き合う相手」と「理系と文系」」で、「生まれ変わるなら、理系と文系のどちらを選ぶか?」「付き合う相手は、理系と文系のどちらが良いか?」を男性・女性/理系・文系の計4種類の人たちに聞いたアンケート結果を眺めました。このアンケート結果を使って遊んでみようと思う時、次に欲しくなるのは、男女別の「理系・文系 比率」ではないでしょうか。男女の割合はそれぞれ48.8%と51.2%程度と聞きますから、大雑把に考えれば「ほぼ同じ」という具合でしょうか。
「「生まれ変わる自分」と「付き合う相手」と「理系と文系」」で、「生まれ変わるなら、理系と文系のどちらを選ぶか?」「付き合う相手は、理系と文系のどちらが良いか?」を男性・女性/理系・文系の計4種類の人たちに聞いたアンケート結果を眺めました。このアンケート結果を使って遊んでみようと思う時、次に欲しくなるのは、男女別の「理系・文系 比率」ではないでしょうか。男女の割合はそれぞれ48.8%と51.2%程度と聞きますから、大雑把に考えれば「ほぼ同じ」という具合でしょうか。
ベネッセの調査結果をみると、高校における男女別の文理コース割合は、次のようになります。
- 男性:理系:48.5%, 文系37.5%,その他 14%
- 女性:理系:28.6%, 文系55.8%,その他 15.6%

ここで、単純化のために、「その他」の人たちを、それぞれの理系文系の比を用いて、理系文系それぞれに振り分けてしまうと(つまり、たとえば、理系比率=理系比率+その他比率*理系比率/(理系比率+文系比率)というように)、理系・文系の比率は、次のようになります。
感覚的にもそんなに違和感を感じない結果です。
- 男性:理系:56%, 文系44%
- 女性:理系:34%, 文系66%
ためしに、もう少し違う単純化もしてみます。たとえば、理系と非理系という分け方にしてみると、次のようになります。
- 男性:理系:49%, 非理系51%
- 女性:理系:29%, 非理系71%
 主役を「理系」という言葉で示されるものと考えるなら、「理系」というものにあくまで焦点を当てるならば、後者の「理系とそれ以外」という分け方をしたものの方が、自然かもしれません。あるいは、強引に「理系」「文系」という2つに分けるとしたならば、前者の割合の方が適切に思えます。
主役を「理系」という言葉で示されるものと考えるなら、「理系」というものにあくまで焦点を当てるならば、後者の「理系とそれ以外」という分け方をしたものの方が、自然かもしれません。あるいは、強引に「理系」「文系」という2つに分けるとしたならば、前者の割合の方が適切に思えます。
と、ここまで準備をしたところで、次の作業はまた明日以降にしてみたい、と思います。
2010-03-19[n年前へ]
■「インターネットショートカットとしてWEB閲覧履歴を保存する」情報検索術 (初出:2006年08月13日)
 「とりあえずググる」を卒業!TOPエンジニアの検索術 という記事を面白く読みました。特に「面白いな」と思ったのが、増井俊之さんの「ネット上で見て回った情報に関しては、ページを表示した瞬間にURLを逐一、取得・記録する」という検索術と、Otsuneさんの「自分のソーシャルブックマークにブックマークした記事は、記事全文をGmailに転送する(という処理をPlaggerというツールを使って行う)」という検索術です。
「とりあえずググる」を卒業!TOPエンジニアの検索術 という記事を面白く読みました。特に「面白いな」と思ったのが、増井俊之さんの「ネット上で見て回った情報に関しては、ページを表示した瞬間にURLを逐一、取得・記録する」という検索術と、Otsuneさんの「自分のソーシャルブックマークにブックマークした記事は、記事全文をGmailに転送する(という処理をPlaggerというツールを使って行う)」という検索術です。
![]() おふた方を始め、他の方も「(自分が知らない)新たな情報を検索する技術の話」ではなく、「自分が、少なくとも一度は眺めたことがある情報、あるいは自分が作り出した情報を、必要なときに取り出す技術」の話をされています。古くは、互いに求め合う主人公二人が不幸にもすれ違い続けるドラマ「君の名は」ではありませんが、出会うことよりも(必要なときに)再会することの方が困難だ、というのはよくありそうな話です。
おふた方を始め、他の方も「(自分が知らない)新たな情報を検索する技術の話」ではなく、「自分が、少なくとも一度は眺めたことがある情報、あるいは自分が作り出した情報を、必要なときに取り出す技術」の話をされています。古くは、互いに求め合う主人公二人が不幸にもすれ違い続けるドラマ「君の名は」ではありませんが、出会うことよりも(必要なときに)再会することの方が困難だ、というのはよくありそうな話です。
増井さん・Otsuneさんの検索術を読み、「自分や他人が生み出した情報に関して、どの程度の範囲の情報を、どのような場所に保管しておき、どのような手順で検索をかけるか」ということを考えてみたくなりました。増井さんの「ネット上の(自分が表示した)ページ全部」のURLという「範囲」やOtsuneさんの「自分のソーシャルブックマークにブックマークした記事全文」という「範囲」、あるいは、「Gmailに情報を保管し、Gmailの検索機能を使う」という保管場所や検索手順を参考にしながら、私も同様のことをやってみることにしました。
といっても、ただ単純に先人の検索術を合体させ、「ネット上の(自分が表示した)ページ全部」の「全文」を自分のPC上に保存し、(必要なときにGoogle Desktopなどを使って)PC上で検索をかける、というやり方です。ただし、先人が作ったレシピ(調理法)に多少のスパイスを加えて、自分なりの調理をしてみることにしました。
そこで、まずは、その作業をするためのアプリケーションを作ってみました。それが、「眺めた全WEBページの内容を、眺めた瞬間に、本文が埋め込まれ、サムネイル画像を付けられたインターネット・ショートカットとして保存するアプリケーション(ブックマーク機能付き)」です。「自分が読んだページの内容テキストとサムネイル画像」を全て「自分のPC内に保存しておく」アプリケーションです。
![]() このアプリケーションは、「インターネット・ショートカット」というWindowsで使われる標準機能の中に、WEBページの全文を埋め込み、WEBページのサムネイル表示機能も実現している(検索もWindowsのファイル検索でも構わない)、というちょっと面白い実装になっています。また、ブックマーク時に保存されるサムネイル画像が「(ページ中の)今眺めている場所」で、「URLで示されたページのトップ(もしくはアンカー部)のサムネイル画像」ではない(つまりアンカーがない部分を後で眺めやすい、かもしれない)、というところなども少し面白いかもしれません。
このアプリケーションは、「インターネット・ショートカット」というWindowsで使われる標準機能の中に、WEBページの全文を埋め込み、WEBページのサムネイル表示機能も実現している(検索もWindowsのファイル検索でも構わない)、というちょっと面白い実装になっています。また、ブックマーク時に保存されるサムネイル画像が「(ページ中の)今眺めている場所」で、「URLで示されたページのトップ(もしくはアンカー部)のサムネイル画像」ではない(つまりアンカーがない部分を後で眺めやすい、かもしれない)、というところなども少し面白いかもしれません。
ところで、ドラマ「君の名は」の冒頭はいつも、「忘却とは忘れ去ることなり」というナレーションで始められていました。今なら、とりあえず相手の名前でググれば相手を見つけることができたりもしそうですが、それでも「忘却・忘れてしまう」ことばかりだと思います。あなたの検索術は、「自分や他人が生み出した情報に関して、どの程度の範囲の情報を、どのような場所に保管しておき、どのような手順で検索をかけるもの」なのでしょう? あなたの生活パターン・あなたの性格に合った面白い検索術は、どんなものなのでしょうか?
2010-03-20[n年前へ]
■「理系か文系か」でわかる!?「恋愛好感度」シミュレータ
 「「生まれ変わる自分」と「付き合う相手」と「理系と文系」」で書いたGirls Labに掲載されていた「付き合う相手は、理系と文系のどちらが良いか?」を男性・女性/理系・文系の計4種類の人たちに聞いたアンケート結果と、「男女別 理系・文系 比率 を出してみよう」で算出した
「「生まれ変わる自分」と「付き合う相手」と「理系と文系」」で書いたGirls Labに掲載されていた「付き合う相手は、理系と文系のどちらが良いか?」を男性・女性/理系・文系の計4種類の人たちに聞いたアンケート結果と、「男女別 理系・文系 比率 を出してみよう」で算出した
という数値から、『「理系か文系か」でわかる!?「恋愛好感度」シミュレータ』というものを作ってみました。自分と気になる相手の情報を入れると、相手が自分に対して「付き合いたい」「付き合いたくない」という気持ちをどんな割合で感じている・持っているだろうか、ということを計算する「恋愛好感度 予報器」です。
- 男性:理系:56%, 文系44%
- 女性:理系:34%, 文系66%
下のフォームが、その『「理系か文系か」でわかる!?「恋愛好感度」シミュレータ』です。JavaScriptを使っているので、JavaScriptを有効にしておかないと動作しません。また、HeartRailsの円グラフ作成WEB APIを使用しています。
この「理系か文系か」でわかる!?「恋愛好感度」シミュレータで適当に遊んでみると、結構面白いようにも思います。しかし、こんな風に予想結果をグラフで実際に眺めてしまうと、「理系」を選びたくなくなる人が増えてしまうかも?なんて一瞬考えたりしますが、こんな結果に左右されたりはしないですよね、きっと。
2010-03-21[n年前へ]
■「楽しいキャンパスライフ」と「文系と理系」
「理系か文系か」でわかる!?「恋愛好感度」シミュレータ で、こう書きました。
この「理系か文系か」でわかる!?「恋愛好感度」シミュレータで適当に遊んでみると、結構面白いようにも思います。しかし、こんな風に予想結果をグラフで実際に眺めてしまうと、「理系」を選びたくなくなる人が増えてしまうかも?なんて一瞬考えたりしますが、こんな結果に左右されたりはしないですよね、きっと。
安斎育郎・板倉聖宣・滝川洋二・山崎孝「理科離れの真相 (ASAHI NEWS SHOP)
」を読んでいると、こんな一節がありました。
先輩に、「大学で理系に入ったらレポートや実験ばかりで遊ぶ時間もないよ。就職しても給料が高いわけでないし、上にも上がれない。それに女の子にモテない」と忠告され、結局、経済学部に進んでしまいました。
 そういえば、経済学者の森永卓郎先生から、こんな言葉を聞いたことがあります。
そういえば、経済学者の森永卓郎先生から、こんな言葉を聞いたことがあります。
物理化学をやろうと思って、東大の理科Ⅱ類に入りました。ところが、毎日、ミミズやカエルの解剖といった実験を夜中までやらされるわけです。そんなとき、文科Ⅱ類の連中を見ると、彼女を連れて楽しいキャンパスライフを送っていました。「あっちのほうがいいな」と思って転部し、経済学へ足を踏み入れてしまったんです。当時、女の子とすごく付き合いたかったんですね。
「理系か文系か」でわかる!?「恋愛好感度」シミュレータ の結果グラフとともにこれらの言葉を眺めると…何だか「なるほど説得力があるなぁ」と思わされますね。
2010-03-22[n年前へ]
■「Mathematica からRuby on Railsのモデルを使う」のメモ
 以前、「Mathematica からRuby on Railsのモデルを使う」でメモした、Mathematica User Conference 2009の資料、
Using Ruby on Rails Models with Mathematicaの内容を簡単にメモ書きしたので、ここに書いて(貼り付けて)おきます。
以前、「Mathematica からRuby on Railsのモデルを使う」でメモした、Mathematica User Conference 2009の資料、
Using Ruby on Rails Models with Mathematicaの内容を簡単にメモ書きしたので、ここに書いて(貼り付けて)おきます。
この資料は、大きく分けて次の4つの内容からなります。
- Rubyの紹介
- Ruby on Railsの紹介
- Mathematicaから直接SQLデータベースにアクセスする実践例 1つと、Ruby on RailsのActive RecordをMathematicaから使う実践例2つ
- MathematicaからRailsアプリで作成したWEB APIにアクセスする実践例1つ
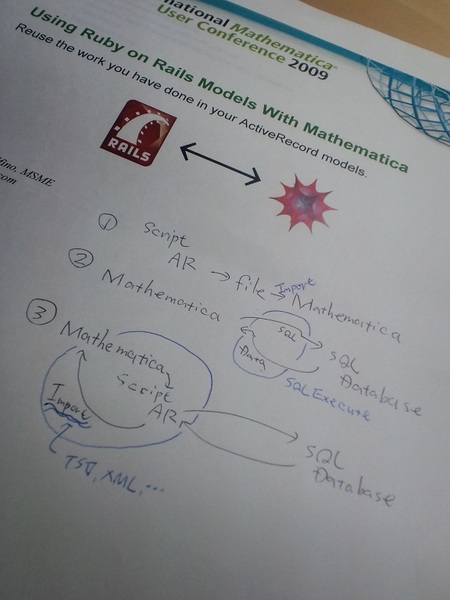 最後の「Mathematicaから直接SQLデータベースにアクセスする実践例 1つと、Ruby on RailsのActive RecordをMathematicaから使う実践例2つ、さらにrailsで作成したWEB APIにアクセスする実践例1つ」がどのようなものかを描くと、下の図のような具合です。1と3がactive Record(AR)を使った場合の処理で、2がMatheematicaから直接SQLサーバを叩く場合の例です。さらに、4番目の例は、RailsでWEB APIを作成する、という、まさに「疎」な結合の例です。この4番目の例は、…そもそも、MathematicaとRubyの両方を知っている人・そもそも作ることができる人しか楽しめないような気がしますから(人が一度に新しい事を知ることができるのは”ひとつ”まで、だと私は思っています)、「実際に役に立つ・新しい情報として楽しむことができる」のは3番目の例まで、かもしれません。
最後の「Mathematicaから直接SQLデータベースにアクセスする実践例 1つと、Ruby on RailsのActive RecordをMathematicaから使う実践例2つ、さらにrailsで作成したWEB APIにアクセスする実践例1つ」がどのようなものかを描くと、下の図のような具合です。1と3がactive Record(AR)を使った場合の処理で、2がMatheematicaから直接SQLサーバを叩く場合の例です。さらに、4番目の例は、RailsでWEB APIを作成する、という、まさに「疎」な結合の例です。この4番目の例は、…そもそも、MathematicaとRubyの両方を知っている人・そもそも作ることができる人しか楽しめないような気がしますから(人が一度に新しい事を知ることができるのは”ひとつ”まで、だと私は思っています)、「実際に役に立つ・新しい情報として楽しむことができる」のは3番目の例まで、かもしれません。
ちなみに、1の例は、RubyスクリプトからActive Recordを使い、中間ファイルを作り、そのファイルを介してMathematicaでActive recordモデルのデータを読み込む例で、3の例は中間ファイル無しに(けれど、原理的には1と同じやり方でSQLサーバ内のARモデルにアクセスするものです。

データを管理するのはSQLサーバで、(そのデータに対して)演算処理を行うのはMathematicという役割分担、そんな処理分担を使って作業してみたい人は、特に「そんなことをしてみたいけれど、よくやり方がわからない人」は一回眺めてみると良いと思います。とても、わかりやすい資料で、「技術紹介資料は、かくあるべし」とすら感じさせる資料です。とはいえ、この資料を楽しめるのは、MathematicaもRubyもRailsも、そのいずれをも少しはかじったことがある人に限られるのかもしれません。
こういう資料を眺めていると、この実践例は、MathematicaからRuby on Railsのactive Record モデルのデータを使う場合ですが、その逆に、Ruby on Railsのactive Record モデルにMathematicaの機能をメソッドとして実装した実践例も作りたくなりますね。

2010-03-23[n年前へ]
■「ロマンティックな恋の有効期限」は「一年間に限る」!? (初出:2005年12月30日)
![]() 「情熱的な恋は一年間しか続かない」というニュースを、先月末、読みました。イタリアのパビア大学の研究者が、さまざまな人たちの血液中の神経成長因子(NGF)の変化を調べてみたところ、 「つきあい始めたばかりの恋人たち」のNGF血液中濃度が「他のつきあいが長い恋人たちや、恋人がいない人たち」よりも高かった、というのです。そして、「つきあい始めたばかりの恋人たち」も、二人のつきあいがさらに続いて一年ほど経ってしまうと、多くの場合、「他のつきあいが長い恋人たちや、恋人がいない人たち」と同じ程度まで減少してしまっていたというのです。
「情熱的な恋は一年間しか続かない」というニュースを、先月末、読みました。イタリアのパビア大学の研究者が、さまざまな人たちの血液中の神経成長因子(NGF)の変化を調べてみたところ、 「つきあい始めたばかりの恋人たち」のNGF血液中濃度が「他のつきあいが長い恋人たちや、恋人がいない人たち」よりも高かった、というのです。そして、「つきあい始めたばかりの恋人たち」も、二人のつきあいがさらに続いて一年ほど経ってしまうと、多くの場合、「他のつきあいが長い恋人たちや、恋人がいない人たち」と同じ程度まで減少してしまっていたというのです。
それを、強引に言ってしまうと「恋の高まり度合い」はその神経成長因子(NGF)の量で推定できるかもしれなくて、さらに「恋の高まり」は一年ほどしか続かない…というわけです。
もちろん、恋の高まり(とは結論ずけれられませんから、きちんと書けば、血中NGF濃度の高まりですね)が必ず一年で終わるというわけではなく、単に「多くの場合は」という話です。ロマンティックな恋の有効期限は「一年間に限る」かもしれない、というのです。今、付き合っている恋人たちにはちょっと悲しい未来を予言する研究結果です。
![]() さて、あなたはどんな時に「恋の高まり」を感じたでしょうか?それは、恋人とつきあい始める前後でどのように変わったのでしょうか?あるいは、それから付き合い始めて時間が経った後、どんな風に変わっていったのでしょうか?いつも恋人と会うときには、新鮮でロマンティックな気持ちになるのでしょうか、それとも落ち着いた気分(血中NGF濃度も)になるのでしょうか…? そして、相手と自分の間でその気分に違いはあったりするものなのでしょうか…?
さて、あなたはどんな時に「恋の高まり」を感じたでしょうか?それは、恋人とつきあい始める前後でどのように変わったのでしょうか?あるいは、それから付き合い始めて時間が経った後、どんな風に変わっていったのでしょうか?いつも恋人と会うときには、新鮮でロマンティックな気持ちになるのでしょうか、それとも落ち着いた気分(血中NGF濃度も)になるのでしょうか…? そして、相手と自分の間でその気分に違いはあったりするものなのでしょうか…?
もしかしたら・・・逆説的に響くかもしれませんが、ずっと同じ気分でいるために、いつも少しづつ変わり続けることも必要だったりするのかもしれません。
2010-03-24[n年前へ]
■眺めた風景を「ジオラマ」にしたい。
 「ジオラマ」な世界を作りたい。つねづね、そう感じてはいたのだけれど、なかなか実際に行動に移す、ジオラマな世界を作ってみる、ということはできずにいた。けれど、「東急東横線渋谷駅 オリジナルジオラマ(完成品)」を見て、そのジオラマ世界を作って・遊んでみたい気持ちが湧いてきた。
「ジオラマ」な世界を作りたい。つねづね、そう感じてはいたのだけれど、なかなか実際に行動に移す、ジオラマな世界を作ってみる、ということはできずにいた。けれど、「東急東横線渋谷駅 オリジナルジオラマ(完成品)」を見て、そのジオラマ世界を作って・遊んでみたい気持ちが湧いてきた。
「東急東横線渋谷駅」でも遊んでみたいけれど、15万円ナリともなると、喉から手は出るけれど、財布をどんなに力一杯降ったとしてもそんなお金は出てこない。
 そこで、「非ユークリッド写真連盟」「非人称芸術連盟」「糸崎公朗・益田隆・井原清人」…つまりは、彼らの「フォトモ」を、まずは、組み立てて遊んでみることにした。フォトモは街中で撮影した被写体を組み合わせて、ジオラマを作る。色々な風景がフォトモとして記録されているけれど(作例)、実際に印刷できるサイズの型紙をOLYMPUSのサイトからはダウンロードすることができる。これなら、カラープリンタで型紙を印刷して、ハサミとノリを使って組み立てるだけで、ジオラマの「小さいけれど広大に感じられる世界」を自分の手で作り上げることができる。
そこで、「非ユークリッド写真連盟」「非人称芸術連盟」「糸崎公朗・益田隆・井原清人」…つまりは、彼らの「フォトモ」を、まずは、組み立てて遊んでみることにした。フォトモは街中で撮影した被写体を組み合わせて、ジオラマを作る。色々な風景がフォトモとして記録されているけれど(作例)、実際に印刷できるサイズの型紙をOLYMPUSのサイトからはダウンロードすることができる。これなら、カラープリンタで型紙を印刷して、ハサミとノリを使って組み立てるだけで、ジオラマの「小さいけれど広大に感じられる世界」を自分の手で作り上げることができる。

こんなジオラマの世界をみると、実際に「自分が眺めた景色」をフォトモなどの技法を使って小さな立体の世界にしてみたくなる。街中を歩くと、目の前の景色の中に、カメラの中に残したい建物や場所がたくさん浮き上がってくる。

2010-03-25[n年前へ]
■笑いを止められない”怪作”「大河ドラマ入門」
 地下鉄大江戸線の中で、新書を読みながら、不気味に笑い声を発する人を見かけたとしたら、それは私だったかもしれない。
地下鉄大江戸線の中で、新書を読みながら、不気味に笑い声を発する人を見かけたとしたら、それは私だったかもしれない。
私が手にしていた本は、小谷野敦「大河ドラマ入門 (光文社新書)」というもので、一言で言うなら、これはまさに「怪作」である。著者人による大河ドラマ出演者たちのイラストが最高に面白い。そのイラストを見て「大笑いする」というのが、まずは、この本を一番楽しめる読み方だと思う。
本屋に並ぶ本、あるいは、同人誌として売られる本、どんなイラストを基準にしても「ここまでヒドいイラストを見たことはないかも!?」と思わせるほどの超異次元の「イラスト」を眺めていると、「笑い」を堪えることは到底できないはずだ。(6点ほど、他の人によるイラストがある。それらは、それは素人にしては、なかなかに巧いと思う)。このイラストを眺め、そして、大笑いするためだけにでも、この本を手に取ってみる価値はあると思う。
たとえば、下の写真はそんなイラストの一部である。この4人が誰だかわかるだろうか。確かに、冷静に眺めてみれば、それぞれの人に似ているようにも見える。しかし、これは人間というより河童か何かの妖怪を描いた図に見えてくる。そこが、無性に面白い。基本的に、この本のイラスト群は、妖怪大図鑑である。

ちなみに、上の写真のイラストは、左から「斎藤洋介」「榎本明」「草刈正雄」「小池栄子」である。こういったイラストを、疲れた深夜に眺めたら、もう笑いが止まらなくなると思う。
2010-03-26[n年前へ]
■男女別・年齢別の「理想のプロポーション」 (初出:2006年09月03日)
ORICON STYLEが「(世代・性別ごとの)理想の(女性に対する)スリーサイズ」という実に興味深い調査を行い、その結果が「不二子伝説崩壊!?男は女よりスレンダーがお好き!」という記事になっています。10・20・30・40代の男性と女性たちに、それぞれの「理想のバスト」「理想のウェスト」「理想のヒップ」をリサーチしてみた結果です。掲載されていた「理想のプロポーション」がわかりやすいように、次の二つのグラフを作ってみました。女性・男性ごとに、(上から)バスト・ウェスト・ヒップの理想を年代ごとに横棒グラフにしてみたものです。


このグラフを眺めた限り、こんなことに気づきます。
- 女性は「下半身の数値ほど、年ごとに(理想)が太く(大きく)なる」
- 男・女で大きく異なる点として、「若い男性の理想のバストが小さい」
女性の場合、バスト・ウェストに関しては「年をとるにしたがって、理想の数値が微増する」だけであるのに対して、「理想のヒップの数値はとても大きくなっています。色々な想像をしてみると、例えば、「(下半身から太る現実を前にして)理想が現実に引き寄せられている」なんていう原因が想像できます。しかも、そんな「現実と理想のすり合わせ」を、同世代男性側の「豊かなヒップが理想だと思うようになる傾向」がさらに支えていたりするのだろうか?なんていう妄想も浮かんできます。
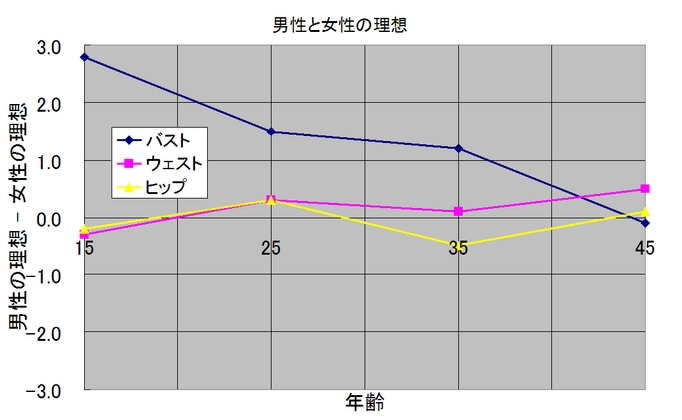 一方、男性の嗜好を眺めると、やはり、若年男性の小胸好き傾向が気にかかるところです。もちろん、「若年男性の小胸好き傾向」は「中年男性の巨乳好き傾向」と言い換えることもできるわけです。しかし、40代の男女の「理想のバスト」の数値がほぼ一致していることを考えると(右上のグラフ参照)、中年男性が巨乳好きだと考えるよりは、やはり若年男性が微乳きだと考える方が自然に思えます。「AカップBカップCカップDカップ~バストを選ぶとしたら君ならどれが好き?」で始まる「バスト占いの歌」で歌われているように、「(自分には存在しない)バストが怖~い」と思っているのかもしれません。そして、そんな「バストへの恐怖」をようやく克服できるのが40代になってから…なのかもしれません。
一方、男性の嗜好を眺めると、やはり、若年男性の小胸好き傾向が気にかかるところです。もちろん、「若年男性の小胸好き傾向」は「中年男性の巨乳好き傾向」と言い換えることもできるわけです。しかし、40代の男女の「理想のバスト」の数値がほぼ一致していることを考えると(右上のグラフ参照)、中年男性が巨乳好きだと考えるよりは、やはり若年男性が微乳きだと考える方が自然に思えます。「AカップBカップCカップDカップ~バストを選ぶとしたら君ならどれが好き?」で始まる「バスト占いの歌」で歌われているように、「(自分には存在しない)バストが怖~い」と思っているのかもしれません。そして、そんな「バストへの恐怖」をようやく克服できるのが40代になってから…なのかもしれません。
一体、この「理想のプロポーション」の数値傾向の裏側にはどんな「現実」があるのでしょうか?あなたなら、どんな推理・想像・妄想をしたくなりますか?
2010-03-27[n年前へ]
■それはホント?「彼女にするなら何カップ?」 アンケート渋谷編 (初出:2006年05月04日)
 私は伊藤理佐の「おいピータン!!
私は伊藤理佐の「おいピータン!!」というマンガが好きなので、「Kiss」というマンガ雑誌を読んでいます。Kissはおそらく20~30歳くらいの女性を読者ターゲットとしている雑誌ですから、30代後半男性の私としては、少し読み辛く感じたりもする雑誌です(高校~大学院時代は「花とゆめ」を読んでいました…)。最近、このKISSの末尾広告ページにアップルC・Dという、バストにかぶせバストを二回りくらい大きくする「バスト増大化パーツ」の広告が掲載されています。そして、宣伝の中に「彼女にするなら何カップ?」「2005年6月に渋谷で20~30代の男性に聞いてみました」という街角アンケートの結果が掲載されているのです。そのアンケート結果が、右上のグラフです。横軸は「カップ」で、縦軸が(そのカップを支持した)「人数」です。宣伝中には、このグラフを使って「断然CカップDカップが支持されている」と書かれていました。
このアンケートが実際に行われたもので、その結果がホントならば、確かに「断然C, Dカップが大人気」のようです。そしてまた、「F, Gカップ辺りもちょい人気?」で「Aカップが好きだ、と言ったのはわずか1人!」「Bカップが好きだ、と言ったのもわずか2人!」だったなんていうこともわかります。BカップとCカップは、わずか1カップの違いにも関わらず、人気度合いが全然違うのです。その差はなんと20倍!です。その人気度の大きな違いは、DカップとEカップの間にもあります。DカップからEカップになると、いきなり人気度合いが1 / 10になるのです…。「アップルC・D」という商品名に素晴らしく一致した(しすぎる)アンケート結果です。
ところで、秋葉原でこんなアンケートをしたら、どういう結果になるのでしょうか?案外「小胸」に人気が集中したりするような気もします。その一方で、「超巨乳」にもやはり人気が出そうな気もします。実際に秋葉原でアンケートを実施したら、一体どんな結果になると思いますか…?

2010-03-28[n年前へ]
■「文書を作ることができない症候群」 (初出:2006年09月15日)
 奥村先生のブログで「少なくともこのページは読むべき」と紹介されていた「Ask E.T.: PowerPoint Does Rocket Science--and Better Techniques for Technical Reports」という記事を読みました。
奥村先生のブログで「少なくともこのページは読むべき」と紹介されていた「Ask E.T.: PowerPoint Does Rocket Science--and Better Techniques for Technical Reports」という記事を読みました。
スペースシャトル・コロンビア号は、打ち上げ時に剥落した液体燃料タンクの断熱材により翼部分が破損したために、帰還中に空中分解してしまいました。この「PowerPoint Does Rocket Science--and Better Techniques for Technical Reports」という記事では、(断熱材による破損の危険性を評価した)ボーイング社の報告書から正当な判断がされなかった理由として、報告書がPower Point のプレゼンテーション・スライドの形式で作られていたことを指摘しています。Power Point のプレゼンテーション・スライドの中で、たとえば、重要な情報が箇条書きの中に埋もれてしまったり…、といったことが遠因となり、断熱材剥落の影響が軽視されることにつながった、というようなことです。
そして、そのような「 Power Point の弊害」を避けるためには、文書スタイルをNature や Science に掲載される論文のようなものとし、そして、Power Point でなく Word などを使って書くべき、というわけです。
 その指摘・解説を読み進めながら、「なるほど。勉強になるなぁ」と思いつつ、「判断を要求されることが多い日常業務中、判断材料をNature や Science に掲載される論文のような文書として渡されても困るよなぁ…」とも感じました。そして、さらに「ここで指摘されている問題より、もっと大きな問題が、実は他にあるのではないか」とも感じたのです。
その指摘・解説を読み進めながら、「なるほど。勉強になるなぁ」と思いつつ、「判断を要求されることが多い日常業務中、判断材料をNature や Science に掲載される論文のような文書として渡されても困るよなぁ…」とも感じました。そして、さらに「ここで指摘されている問題より、もっと大きな問題が、実は他にあるのではないか」とも感じたのです。
その「問題」をひとことで書いてしまえば、「プレゼン・スタイルや論文スタイル…どんな種類の文書であれ、適切な情報を適切な順序・量・構成で文章にできる人なんて非常に少ないのではないか」ということです。「Nature や Science に掲載され論文のような文書」を書けるような人はほとんどいないように思います。あるいは、そういった文章を書くことができる人がいたとしても、その文章の内容(形式ではありません)がそれほど新しいものでなかったり(つまり、単に以前書いた文書の焼き直しだったり)するのではないか、とも思うのです。フォーマット・道具の違いを気にする以前の、実に低レベルな悩みを抱えている段階だったりするように思ったのです。
というわけで、Edward Tufte の周りはいざしらず、道具の違いを気にする以前に、「論理的に話を組み立て、適度な量・構成としてまとめる」ことをまずできるようになりたい!と切望している今日この頃なのです。
2010-03-29[n年前へ]
■「巨大テトラポッド」の作り方 (初出:2005年08月29日)
 右の写真はテトラポッドです。近くに停まっているRV車と比べて眺めてみれば、ずいぶんと大きいことがわかると思います。高さは…、ちょうど5mくらいありそうです。この巨大なテトラポッドは静岡県 富士市近くの田子の浦海岸に置いてありました。なんと、(テトラポッドに書いてある番号を眺めてみると)二百個近く並んでいるようです。テトラポッドが並ぶ景色は、とても壮大でもあり、何だか少し不思議でもあります。
右の写真はテトラポッドです。近くに停まっているRV車と比べて眺めてみれば、ずいぶんと大きいことがわかると思います。高さは…、ちょうど5mくらいありそうです。この巨大なテトラポッドは静岡県 富士市近くの田子の浦海岸に置いてありました。なんと、(テトラポッドに書いてある番号を眺めてみると)二百個近く並んでいるようです。テトラポッドが並ぶ景色は、とても壮大でもあり、何だか少し不思議でもあります。
普通、テトラポッドは海沿いギリギリに設置されているわけですから、(防波堤大好きな釣り師ならともかく)なかなか近くでテトラポッドを眺めることがありません。そこで、近くに寄ってしげしげと眺めていると、「この巨大なテトラポッドをどうやって作ったんだろう?」という疑問が湧いてきました。そして、「こんなに巨大なテトラポッドをどうやってここまで持ってきたんだろう?」という疑問も頭の中でグルグル回り出しました。100トンはありそうな巨大コンクリートを一体どうやってココまで…?という製造法のナゾが不思議に思えてきたわけです。

そこで、周りをさらに眺めているとその秘密が中央部に設置されてありました。その秘密が右の写真です。「その場で(鉄筋コンクリートの)鉄筋を組んで、その周りに『型枠』を組んで」、その『型枠』の中にコンクリートをその場でトクトクと注ぎ込んで、このテトラポッド群を作っていたのでした。つまり、「現場」で全て作りだしていたわけです。この巨大なテトラポッドが作り出されていたのは、工場でも会議室でもなく、「現場」で作り出されていたのです。ヒミツを知ってみれば当たり前の話に思えてきます。…とはいえ、この巨大なテトラポッドを量産しているようすを眺めていると、ヒミツが明らかになった後でも迫力があって、ずいぶんと長い間、見とれてしまいました。
 もしかしたら、私以外にもこんな「巨大テトラポッド」に見とれる人がいるかもしれないので、テトラポッドの「骨」や、立体十字型テトラポッドの生産工場の写真を下に貼り付けておきます。なんだか、立体十字型テトラポッドが、太平洋に浮かぶイースター島で、水平線の彼方を眺めるモアイ像のように見えてくるのは私だけでしょうか?
もしかしたら、私以外にもこんな「巨大テトラポッド」に見とれる人がいるかもしれないので、テトラポッドの「骨」や、立体十字型テトラポッドの生産工場の写真を下に貼り付けておきます。なんだか、立体十字型テトラポッドが、太平洋に浮かぶイースター島で、水平線の彼方を眺めるモアイ像のように見えてくるのは私だけでしょうか?




2010-03-30[n年前へ]
■「脳の本」を買う人はどんな人ですか?
![]() どうしても「これら(とても売れている)『脳の本』はどんな人が読んでいるのか」ということを、知りたかったので、「脳の本
どうしても「これら(とても売れている)『脳の本』はどんな人が読んでいるのか」ということを、知りたかったので、「脳の本
」がどんな人に売れているのでしょうか?と、少しばかり内情を知る人に恐る恐る尋ねてみました。すると、「ライフハック本などを買う層と重なってます」という風に、教えて頂きました。…とすると、次の疑問が湧いてきます。それは、「ライフハック本」というものはどんな人が買うのだろう、ということです。
ところで、「脳の本」を書く苫米地英人さんは、デーモン小暮と同じように、確信的に「お笑い」キャラを自己演出しているのだと私はずっと思っていました。しかし、それは、お笑い好きな私の大いなる勘違いで、丸っきり間違っている「認識」なのでしょうか。…この謎を誰かに解いてほしい、今日この頃なのです。
あなたは、どう思われますか?どのように推理されますか?
2010-03-31[n年前へ]
■東急目黒線大岡山駅と駅周辺の定食屋に張られた”ソースコード”の「募集広告」
 201年03月31日の日経産業に「"とがった頭脳"採用作戦 ワークスAP 東工大周辺に絞る 募集広告にソースコード 読める学生にマト」という記事が載っていました。
201年03月31日の日経産業に「"とがった頭脳"採用作戦 ワークスAP 東工大周辺に絞る 募集広告にソースコード 読める学生にマト」という記事が載っていました。
2009/11/30-12/13まで、東急目黒線大岡山駅と駅周辺の定食屋に、ソフトウェアをプログラミングする際のソースコードが箇条書きされたポスターを掲示。(中略)狙いは東工大の学生。ソースコード広告は、今後も採用活動はソフト開発でずば抜けた能力を持つ技術者を増やす施策の1つ。 日本を代表する理工系大学であれば、ソースコードを苦も無く読める学生は多いと踏んだ。このポスターに、一体、どんなソースコードが記述されていたのか知りたくてたまりません。そのポスター中に記述されたソースコードは、一体どのような動きをするものだったのでしょうか?そしてまただ、一体、どのような言語で書かれたものだったのでしょうか?
東急目黒線大岡山駅や駅周辺の定食屋、たとえば、あの辛い中華料理屋の壁には、一体どのようなコードが書かれていたのでしょう。私と同じように眺めたことがない人ならば、そのポスター画像を眺めてみたいと、思いませんか?