2013-01-22[n年前へ]
■CAPTCHA復元で眺める「単純明快で最適解になっている世界の原理」 
 インターネットの中を広告・宣伝のためのロボットが走り回るようになってからずいぶん経ちました。ロボットから人間を識別するために(ロボットには読めない)CAPTCHAが作られて、けれど、そんなCAPTCHAに人間も悩まされる時代です。
インターネットの中を広告・宣伝のためのロボットが走り回るようになってからずいぶん経ちました。ロボットから人間を識別するために(ロボットには読めない)CAPTCHAが作られて、けれど、そんなCAPTCHAに人間も悩まされる時代です。
MintEyeと呼ばれるCAPTCHAは、スライダーで決められたパラメータを使って変形させた画像を、そのスライダーを動かすことで「普通の画像」に戻すことができた間だけ「あなたは人間だ!」と判断するシステムです。
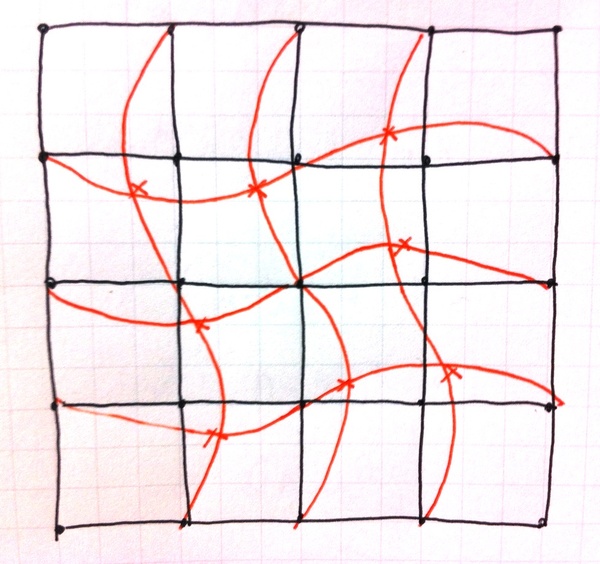 そんなMintEye CAPTCHAを破るのは簡単だ、ほんの数行(実際のところ2行足らず)のPythonコードを書けばいい…という記事”Breaking the MintEye image CAPTCHA in 23 lines of Python”を面白く読みました。内容を簡単に書くと、「エッジ(画像の微分値)の総和が最小になる条件=普通の画像に戻った条件」だ、という具合です。
そんなMintEye CAPTCHAを破るのは簡単だ、ほんの数行(実際のところ2行足らず)のPythonコードを書けばいい…という記事”Breaking the MintEye image CAPTCHA in 23 lines of Python”を面白く読みました。内容を簡単に書くと、「エッジ(画像の微分値)の総和が最小になる条件=普通の画像に戻った条件」だ、という具合です。
![]() 直交座標を手書きで描くと、空間中を最短距離で結んでいる直線群が描かれます。長方形に張られたゴム紐が形作るような、そんな世界を最短・最適に結んでいる座標軸をかき乱したなら、座標軸に沿って描かれる画像(線分)は(大雑把に平均的に眺めてみれば)必ず長くなるのでしょう。
直交座標を手書きで描くと、空間中を最短距離で結んでいる直線群が描かれます。長方形に張られたゴム紐が形作るような、そんな世界を最短・最適に結んでいる座標軸をかき乱したなら、座標軸に沿って描かれる画像(線分)は(大雑把に平均的に眺めてみれば)必ず長くなるのでしょう。
「線分=エッジ(微分)の総和を最小化し、(攪拌された状態から)元の画像に戻す」という数行のコードは、単純明快で美しい!と思います。

2014-12-30[n年前へ]
■壊れかけのプロジェクタで(形状推定)巨乳ビジョン
 神田無線の激安お得な液晶プロジェクタをいじっていたら…VGAコネクタの差し込みがイマイチ変な感じになって、ついにはそのVGAコネクタが(筐体内部で)取れてしまい、カランコロンと中で音がしてる状態になった。仕方がないので、内部を開けてみると、表面実装のコネクタが取れている。
神田無線の激安お得な液晶プロジェクタをいじっていたら…VGAコネクタの差し込みがイマイチ変な感じになって、ついにはそのVGAコネクタが(筐体内部で)取れてしまい、カランコロンと中で音がしてる状態になった。仕方がないので、内部を開けてみると、表面実装のコネクタが取れている。
そんな壊れかけのラジオならぬ壊れかけのプロジェクタを使い、1/10スケールくらいの人形にパターン投影をして、位相シフト法で形状取得をしてみた。ところどころ位相推定に失敗しているところが見受けられるけど、比較的簡単に細かな形状計測ができるのは、なかなかに面白い。

もしも、中2病に掛かる年頃だったなら、絶対ハンディな「巨乳ビジョン」とか作ってみたいかも。


2016-12-12[n年前へ]
■「君の名は。」画風変換アプリをPython/OpenCVで書いてみよう! 〜意外に空変換は簡単? 編〜
 先月下旬頃、映画「君の名は。」画風変換アプリEverfilterが流行っていた。軽く遊んでみた印象は、「空領域抽出処理に破綻が少なく(適切で)、その処理はおそらく普通の枯れた方法を使って、画面の4端辺から領域判定を独立にかけてる」ように感じられた。
先月下旬頃、映画「君の名は。」画風変換アプリEverfilterが流行っていた。軽く遊んでみた印象は、「空領域抽出処理に破綻が少なく(適切で)、その処理はおそらく普通の枯れた方法を使って、画面の4端辺から領域判定を独立にかけてる」ように感じられた。
そこで、普通にやりそうなコードを書いてみたら、空領域抽出がどのくらいの品質が得られるか、確かめてみることにした。手っ取り早く試してみたいというわけで、Python/OpenCVコードを書いてみた。このコードは、入力画像と(入れ替え用の)空画像を読み込んで、グラフカットアルゴリズムが実装されたOpenCVのGrabCut関数を使い、(空がある程度の面積を占めていそうな)画面上半分の領域を対象として空領域を抽出し、その領域に空を合成するという処理を行うものだ。その処理例が、たとえば下に貼り付けた「バンコクの昼風景を夜空の下の街に入れ替えた画像」のようになる(上が入力画像、下が出力画像)。
コードを書いて・試してみた印象は、OpenCVのGrabCut関数を使う程度でも、十分破綻の少ない空領域抽出を行うことができそうで、枯れた(枯れつつある)技術は便利だ!というものだ。実際のところ、「君の名は。」画風変換アプリ程度であれば、使用データ群(入れ替え用画像群)抽出処理も含めて、数日掛からず作ってしまいそうな気がする。


import cv2
import numpy as np
img = cv2.imread("bangkok1s.jpg")
mask = np.zeros(img.shape[:2],np.uint8)
skyimg = cv2.resize(cv2.imread("Starsinthesky.jpg"),
img.shape[1::-1])
bgdModel = np.zeros((1,65),np.float64)
fgdModel = np.zeros((1,65),np.float64)
rect = (0,0,img.shape[1],round(img.shape[0]*0.7))
cv2.grabCut(img,mask,rect,bgdModel,fgdModel,
50,cv2.GC_INIT_WITH_RECT)
mask2 = np.where((mask==2)|(mask==0),0,1).astype('uint8')
mask2 = cv2.blur(mask2,(5,5))
img2 = img*(1-mask2[:,:,np.newaxis])
skyimg = skyimg*mask2[:,:,np.newaxis]
img3 = cv2.addWeighted(skyimg, 1, img2, 1, 2.5)
cv2.imwrite("out.jpg",img3)
cv2.imshow("preview",img3)
cv2.waitKey()


2016-12-23[n年前へ]
■Python/OpenCVで画像多重解像度解析コードを書いてみる
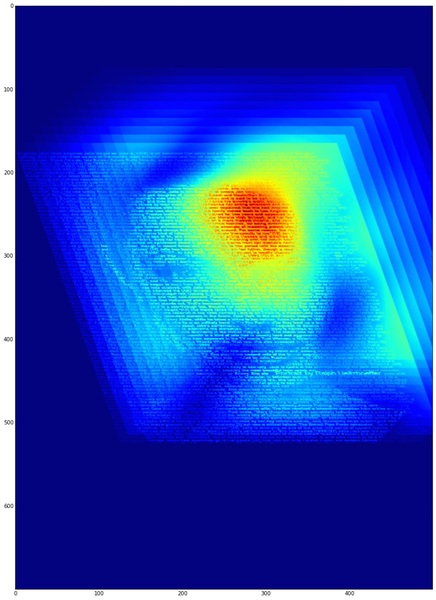 多重解像度解析…といっても直交基底に分解するというような話ではなくて、単に各周波数帯の特性がどの程度含まれるかを眺めるといった用途なら(つまり、ガボール変換やSTFTを掛ける感じの程度の用途なら)、Python/OpenCVを使って十数行で書けるかも?と思い書いてみました。もちろん、実装は簡単第一最優先!というわけで、ガウシアンフィルタ差分で2次元のバンドパスを作成し、それを周波数軸で重ねて眺めてみるというくらいの話です。
多重解像度解析…といっても直交基底に分解するというような話ではなくて、単に各周波数帯の特性がどの程度含まれるかを眺めるといった用途なら(つまり、ガボール変換やSTFTを掛ける感じの程度の用途なら)、Python/OpenCVを使って十数行で書けるかも?と思い書いてみました。もちろん、実装は簡単第一最優先!というわけで、ガウシアンフィルタ差分で2次元のバンドパスを作成し、それを周波数軸で重ねて眺めてみるというくらいの話です。
実際に書いてみたら、ポスト処理含めて約20行くらいになりました。超入門的な画像処理コードですが、1次元〜2次元の多重解像度解析や周波数解析を行うことは意外に多いような気もするので、適当に貼り付けておくことにします。*
*画像処理クラスタからのコメント:
・マルチスケールで眺めるなら、DCゲイン1同士のガウシアン差分をとり、そのL2ノルムを1に正規化しすべし。
・周波数軸は等比的にした上で、ボリューム的表示も等比的比率で重ねたい。
import numpy as np
import cv2
from matplotlib import pyplot as plt
def DOG(img, s, r):
img2=img.astype('uint16')
img2=img2*128+32767
gs = cv2.GaussianBlur(img2,(0, 0), s)
gl = cv2.GaussianBlur(img2,(0, 0), s*r)
return cv2.absdiff(gs, gl)
img = cv2.imread("sample2.jpg",0 )
(h,w)=img.shape
pts1 = np.float32([[0,0],[w,0],[w,h],[0,h]])
pts2 = np.float32([[0,h*1/4],[w*3/4,h*1/4],
[w,h*3/4],[w*1/4,h*3/4]])
M = cv2.getPerspectiveTransform(pts1,pts2)
baseImg = cv2.warpPerspective(
img.astype('uint16'),M,(w,h))
for i in range(100,5,-10):
pts1 = np.float32([[0,0],[w,0],[w,h],[0,h]])
pts2 = np.float32([[0+i,h*1/4-i],
[w*3/4+i,h*1/4-i],[w+i,h*3/4-i],[w*1/4+i,h*3/4-i]])
M = cv2.getPerspectiveTransform(pts1,pts2)
img2 = cv2.warpPerspective(DOG(img, i, 1.05),M,(w,h))
baseImg = cv2.addWeighted(baseImg, 0.9, img2, 0.3, 0)
plt.figure(figsize=(6,6))
plt.imshow(np.array(baseImg))
plt.autoscale(False)
2017-01-29[n年前へ]
■「手持ちスマホ撮影動画からの超巨大開口レンズ撮影」に挑戦してみよう!?
かつて、スマホに搭載されているカメラのレンズはとても小さく、綺麗なボケとは無縁の存在でした。しかし、今や最新のスマホには特殊処理によるボケ生成機能などが備えられています。カメラレンズの光学開口径が小さくとも、たとえば2眼カメラなどを備えて距離情報を取得して、距離情報などからボケを人工的に合成するといった仕組みです。
 そんな最新スマホを持たずとも、大レンズのボケ味を手に入れるために、「手持ちスマホ撮影動画からの超巨大開口レンズ撮影」に挑戦してみました。スマホ動画から巨大開口レンズ撮影の手順はとても簡単、まずは目の前の風景にスマホを向けて・なるべくスマホが平面上を動くように意識しながら(スマホを動かしつつ)動画撮影します。そして、動画の各コマから画像ファイル群を生成し、それぞれの画像が撮影された位置や方向にもとづいて撮影された光情報を加算合成する、というものになります。
そんな最新スマホを持たずとも、大レンズのボケ味を手に入れるために、「手持ちスマホ撮影動画からの超巨大開口レンズ撮影」に挑戦してみました。スマホ動画から巨大開口レンズ撮影の手順はとても簡単、まずは目の前の風景にスマホを向けて・なるべくスマホが平面上を動くように意識しながら(スマホを動かしつつ)動画撮影します。そして、動画の各コマから画像ファイル群を生成し、それぞれの画像が撮影された位置や方向にもとづいて撮影された光情報を加算合成する、というものになります。
細かい手順は、スマホ撮影動画(の展開画像をもとに) Bundler: Structure from Motion (SfM) から出力された刻々のカメラ位置・方向や特徴点情報ファイル(bundler.out)を読み込み、それらのカメラ情報にもとづいて、刻々の撮影画像をレンズ開口面に沿った(同じ方向を向く平行カメラが存在していた場合の)光線画像を位置・角度ズレを踏まえて重ねることで、任意のピント位置に焦点を合わせた超巨大開口レンズ撮影画像を生成する…というものです。
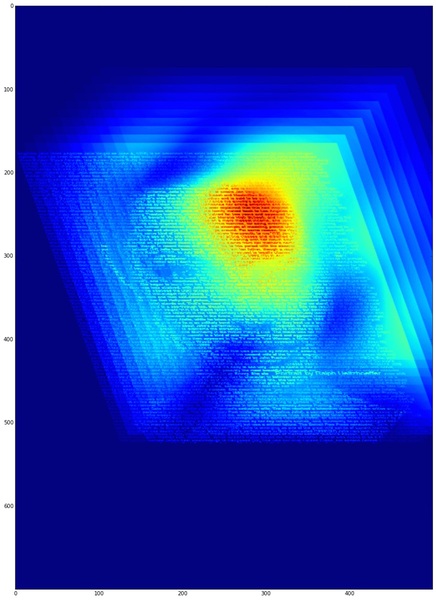
試しに、iPhoneを約1.5m×1.0mの範囲で動かしつつ動画撮影し、つまり、レンズ直径約1.5mに相当する範囲で動かしつつ動画撮影し、その画像群から開口合成により超巨大カメラの撮影画像を作り出してみた結果が右上の画像です。
右上画像を眺めてみても、良好なボケ味どころか、全くピントが合っていない画像にしか見えません。直径が1mを超える開口を持つカメラレンズとなると焦点深度もとても浅くなるのでピントがなかなか合わない…というわけでなく、手持ち撮影動画からのカメラ位置・方向精度が低いせいか、単一カメラに平行合成した後のズレが大きいようです。
ちなみに、試しに各画像を(撮影方向による傾きを補正しつつ)位置毎に並べてみると、下の画像のようになります。動画撮影からのカメラ位置推定精度が果たして不十分なのかどうか、次は撮影カメラ位置を精度良く知る事ができる撮影治具でも作り、また再挑戦してみたいと思います。
上記処理のコード手順、Python/OpenCVで書いたコード処理手順は、bundler.outからカメラ位置・方向・焦点距離や歪みパラメータを読み込み、cv2.initUndistortRectifyMapにカメラ情報を渡して、各撮影画像の向き補正用のホモグラフィーマップを作成してremapで変換した後に、各撮影画像を加算合成するという手順です。

Bundlerの出力ファイルを読み込んでライトフィールド合成を行うOpenCV/Pythonコード、まだまだ間違い含まれているような気もしますが、とりあえずここに貼り付けておくことにします。
import cv2
import numpy as np
from matplotlib import pyplot as plt
from PIL import Image
import math
%matplotlib inline
class camera:
def __init__(self):
self.f = 1.0
self.k1 = 0.0
self.k2 = 0.0
self.R = [[0.0,0.0,0.0],[0.0,0.0,0.0],[0.0,0.0,0.0]]
self.T = [0.0,0.0,0.0]
def readBundlerOut( filePath ):
f = open(filePath, 'r')
list = f.readlines()
f.close()
numberOfCameras = int((list[1].split())[0])
cameras = []
for i in range(numberOfCameras):
aCamera = camera()
fk1k2 = [float(j) for j in list[5*i+2].split()]
aCamera.f = fk1k2[0]
aCamera.k1 = fk1k2[1]
aCamera.k2 = fk1k2[2]
rot = []
for j in range(1,4):
rot.append( [float(k) for k in list[ 5*i+2+j ].split()] )
aCamera.R = rot
aCamera.T = [float(k) for k in list[ 5*i+2+4 ].split()]
cameras.append(aCamera)
return cameras
def readImageList( listPath, imageDirPath ):
f = open(listPath, 'r')
list = f.readlines()
list = [ i.rstrip() for i in list ]
f.close()
list = [imageDirPath+fileName for fileName in list]
return list
class lightField:
def __init__(self):
self.w = 2000
self.h = 2000
def loadImageListAndMakeLightField( self,
imagePathList, cameraList, workList, scaleA ):
self.cimg = np.zeros((self.h, self.w,3), dtype=np.uint8)
sum = 1.0
for i in workList:
img = cv2.imread( imagePathList[i], cv2.IMREAD_COLOR )
h, w = img.shape[:2]
imageHeight = img.shape[0]
imageWidth = img.shape[1]
focalLength = cameraList[i].f
principalPointX = 0.500000
principalPointY = 0.500000
distCoef = np.array([ 0.0, 0.0, 0.0, 0.0, 0.0 ])
cameraMatrix = np.array([
[focalLength,
0.0,
imageWidth * principalPointX],
[0.0,
focalLength,
imageHeight * principalPointY],
[0.0, 0.0, 1.0]
])
newCameraMatrix, roi = cv2.getOptimalNewCameraMatrix(
cameraMatrix,
distCoef,
(img.shape[1], img.shape[0]),1,
(img.shape[1], img.shape[0]) )
rotMatrix = np.array( cameraList[i].R )
map = cv2.initUndistortRectifyMap(
newCameraMatrix,
distCoef,
rotMatrix,
newCameraMatrix,
(img.shape[1], img.shape[0]),
cv2.CV_32FC1)
undistortedAndRotatedImg = cv2.remap( img,
map[0], map[1],
cv2.INTER_LINEAR )
scale = 1.0
pt3 = np.array(cameraList[i].T) - np.array(cameraList[0].T)
x = ( self.w/2.0 - pt3[0] * scale * scaleA )
y = ( self.h/2.0 - pt3[1] * scale * scaleA )
pts1 = np.float32( [[0, 0],
[w, 0],
[w, h],
[0, h]])
pts2 = np.float32( [[x, y],
[x + w*scale, y],
[x + w*scale, y + h*scale],
[x, y + h*scale]] )
M = cv2.getPerspectiveTransform( pts1, pts2 )
img2 = cv2.warpPerspective(
undistortedAndRotatedImg, M, (self.w, self.h) )
sum = sum + 1.0
self.cimg = cv2.addWeighted(
self.cimg, (sum-1) / sum,
img2, (1.0) / sum, 0)
def showImage(self):
plt.figure( figsize=(14,14) )
plt.imshow( np.array(self.cimg2) )
plt.autoscale( False )

