■数字文字の画像学 
縦書きと横書きのバーコード
始まりはまたしても「物理の散歩道」である。
- 「新物理の散歩道」 第一集 ロゲルギスト 中央公論社
さて、その中の-横組・縦組と二つの目-という一節中の外山滋比古氏の発言が実に面白い。
「日本の漢字は横の線が発達してますから、横から読みますと目に抵抗が少なくて読みにくいですね。ヨーロッパの文字は縦の線が非常に発達していて、横に読むと非常に能率がいいわけです。数字でも縦の棒を引いて、Ⅰ、Ⅱ、Ⅲ、Ⅳ....としますが、和数字は横に線を引いて一、二、三...となります。...」という発言である。
- 文字は読む方向に対して垂直な線が多い
- また、読む方向に対して水平な線は少ない
- いずれも目のスキャン方向に対して垂直な線が多い
そこで、今回その確認と考察を行ってみることにした。サンプルとしては、外山滋比古氏の発言の通り、ローマ数字と漢字数字を用いることにする。
まずは、本来の書き方の方向に数字を並べた画像である。画像サイズは128x128である。後の処理のために、縦横比を同じにした。すなわち、本来の画像のアスペクト比とは異なる。
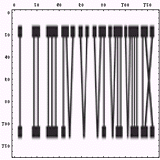 |  |
この二つの画像を読む方向に目を走らせると、まるでバーコードのようである。以前、
の時に作った郵便カスタマバーコードを参考に示してみる。考えてみると、バーコードは検出手段をバーコードの進行方向に走らせて、情報を読み取るわけである。人間が数字の羅列を読み取るのも、数字文字列上に目を走らせるのであるからまったくもって同じである。
一次元バーコードを考えた時、バーコードのバーは進行方向に対して垂直なものがほとんどである(若干のアジマス角を持つものもあるが)。バーコードを読み取る方向に対してのみ情報が書き込まれているのだから、それ以外の方向には等方的であるのが当然である。もし、そうでなかったらスキャン位置がちょっとずれただけでデータの読み取りができなくなってしまう。
そう考えると、先の数字文字に関する
- 読む方向に対して垂直な線が多い
- 読む方向に対して水平な線は少ない
また、本来の数字文字を並べる方向が読み書きの方向と異なる場合を以下に示す。
 |  |
さて、画像を並べるだけではつまらないので、
- 本来の書き(並べ)方
- 本来の書き方と異なる書き(並べ)方
人間の目が数字文字列上をスキャンしていくときに、選られる情報量を考えるために、読む方向に対して画像を微分したものを示す。もう少し正確に言えば、微分値の絶対値を画像にしたものである。
まずは、本来の書き(並べ)方のものを示す。
 818892 |  923836 |
微分画像の下に示した数字は微分(して絶対値)画像のピクセルの値の総和である。これをスキャン方向に対して選られる情報量の指標として扱うことにする。「スキャン方向に対して変化量が大きいということは、情報量が多い」ということだからである。
次に、本来の書き方と異なる書き方の場合を示す。
 536383 |  632338 |
それでは、「微分(して絶対値)画像のピクセルの値の総和」を比較してみることにしよう。
| 本来の書き方の場合 | 818892 | 923836 |
| 本来の書き方と異なる場合 | 536383 | 632338 |
ローマ数字、漢字数字の両方で、本来の書き方の方が(読む方向に対する)画像の変化量が大きいことがわかる。すなわち、「目のスキャン方向に対して選られる情報量」が多く、そうでない方向には冗長なのである。エラー発生率が小さくなるのである。本当にバーコードそのものである。文字はバーコードの祖先だったのである。
さて、「文字の画像学」も色々と面白そうなので、これからちょこちょこ遊んでいこうと思う。