2016-07-30[n年前へ]
■続 5000円で”光もモノも3次元的に記録するライト・フィールド・カメラ”を作ってみよう!? 
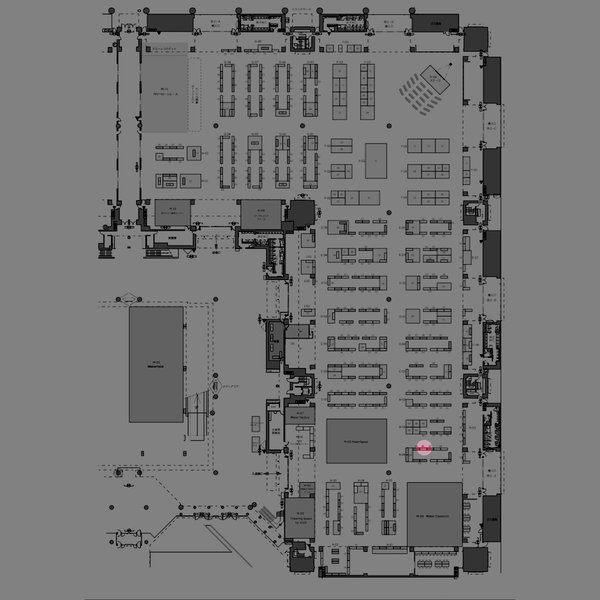
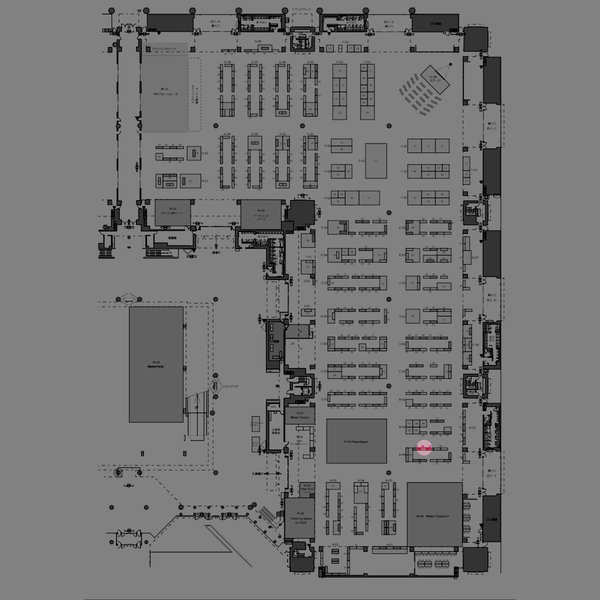 一週間後の8月6日(土)と7日(日)には、東京ビッグサイトで開催されるメイカーフェアー東京2016で、5000円ポッキリで作る「”光もモノも3次元的に記録するライトフィールド・カメラ”」や、Ricoh Theta S で作る全天周多視点(簡素ライトフィールド)カメラを展示する予定です。ちなみに、展示ブースは、A-06-06という覚えやすいけれど、右図のように少しわかりにくい場所で、「理科教育研究フォーラム」という名前で出しています。
一週間後の8月6日(土)と7日(日)には、東京ビッグサイトで開催されるメイカーフェアー東京2016で、5000円ポッキリで作る「”光もモノも3次元的に記録するライトフィールド・カメラ”」や、Ricoh Theta S で作る全天周多視点(簡素ライトフィールド)カメラを展示する予定です。ちなみに、展示ブースは、A-06-06という覚えやすいけれど、右図のように少しわかりにくい場所で、「理科教育研究フォーラム」という名前で出しています。
5000円で自作するライトフィールド・カメラは、下図の説明用パネルのように、凹レンズアレイシートに写し出された景色を1台のUSBカメラで撮影することで、平面上の各領域から周囲各方向の「光」を撮影・処理するというものです。凹レンズアレイシートには12×7=84視点の景色が写し出されているので、84の異なる視点位置から眺めた光線場を撮影し、そしてさまざまな処理を行う…というカメラです。(全天周ライトフィールドカメラについての説明は、明日にでも書いてみることにします)

たとえば、下の動画は5000円ライトフィールドカメラで写している風景動画に関して、好きな箇所(距離)に焦点を合わせ、そしてそれ以外の領域をぼかすリフォーカス処理をしている動画です。安い1台のUSBカメラで全視点の画像を撮影しているので、1視点あたりの画像解像度はせいぜい200×200ピクセルと低解像度になってはしまいますが、自分が組み立てたカメラで簡単な処理コードを書くだけで、リフォーカス処理ができるのは結構楽しいものです。
また、下の動画は光合成による開口径(絞り)可変処理を試している時に写し出されているものです。こうした後処理を必要とする状況がどれだけあるかは…疑問なところもありますが、やはり安く簡単に作ることができるお手製のシステムで、こうした実験ができるのは面白いと思います。
というわけで、2016年の8月6日、7日は東京ビッグサイトでお待ちしております。いらっしゃる方がいましたら、「○×分後くらいに遊びに行くかも!」と伝えて頂ければ、(他を眺め歩きがちな)説明員も戻るようにしようと思います。

2016-08-12[n年前へ]
■自作ライトフィールドカメラ撮影画像をライトフィールド印刷してみよう!?
 Maker Faire Tokyo 2016(8/6, 7) では、自作的超巨大ライトフィールドカメラを5000円で作り、その他Ricoh Theta S 用全天周多視点撮影画像用キットなどと一緒に展示してきました。その二日間の夏休み日記はまた後で書くことにして、今日はMaker Faire Tokyo 2016での展示はしなかった(できなかった)自作ライトフィールドカメラ撮影画像からのライトフィールド印刷について書いてみることにします。
Maker Faire Tokyo 2016(8/6, 7) では、自作的超巨大ライトフィールドカメラを5000円で作り、その他Ricoh Theta S 用全天周多視点撮影画像用キットなどと一緒に展示してきました。その二日間の夏休み日記はまた後で書くことにして、今日はMaker Faire Tokyo 2016での展示はしなかった(できなかった)自作ライトフィールドカメラ撮影画像からのライトフィールド印刷について書いてみることにします。
 カラー印刷をした透明なシートを重ねたり、あるいは、LCDの液晶部分を重ねて立体映像を表現する手法は20年くらい前からありました。そんな手法をより身近に使えるようにするサービスをLUMIIが始めました。具体的には、少し距離が離れた2面のカラー印刷をして、その重ね合わせで所望のライトフィールド画像を近似してやろうというものです。…今日は、超巨大な自作ライトフィールドカメラ(作成費用5000円ナリ)の撮影画像から、Lumii風の3D表示2Dプリントの画像データ作り、どんな風に見えるか軽くシミュレーションした結果を、書いておくことにします。
カラー印刷をした透明なシートを重ねたり、あるいは、LCDの液晶部分を重ねて立体映像を表現する手法は20年くらい前からありました。そんな手法をより身近に使えるようにするサービスをLUMIIが始めました。具体的には、少し距離が離れた2面のカラー印刷をして、その重ね合わせで所望のライトフィールド画像を近似してやろうというものです。…今日は、超巨大な自作ライトフィールドカメラ(作成費用5000円ナリ)の撮影画像から、Lumii風の3D表示2Dプリントの画像データ作り、どんな風に見えるか軽くシミュレーションした結果を、書いておくことにします。
 やってみたことは簡単で、自作ライトフィールドカメラの12×7=84視点の撮影画像から、中央の3x3視点だけを抽出し、そのライトフィールド画像を近似表現するための(少し距離が離れた)2面のカラー画像をちょうどCT撮影による断面推定と同じような処理で推定し、それらをバックライト越しに並べたさまをシミュレーションで眺めてみたというものです。
やってみたことは簡単で、自作ライトフィールドカメラの12×7=84視点の撮影画像から、中央の3x3視点だけを抽出し、そのライトフィールド画像を近似表現するための(少し距離が離れた)2面のカラー画像をちょうどCT撮影による断面推定と同じような処理で推定し、それらをバックライト越しに並べたさまをシミュレーションで眺めてみたというものです。
シミュレーション結果を眺めてみると、立体的に感じられなくもないけれど、本家本元に比べると月とスッポン的な感じです。というわけで、明日以降またがんばってみる…と日記には書いておくことにしましょうか。




2016-08-13[n年前へ]
■続 自作ライトフィールドカメラ撮影画像をライトフィールド印刷してみよう!?
 今日は、自作ライトフィールドカメラ撮影画像をライトフィールド印刷してみよう!?でシミュレーションを使って確認してみた、薄層(多層)的・CT的なテクニックで3Dな世界を通常プリンタで表現するライトフィールド印刷を、実際に試してみました。「ライトフィールド」という言葉は一般的ではありませんが、ここでは「観る方向によってどんな色・明るさが見えるか」という程度の意味だと考えておいて下さい。つまり、「観る方向に応じて、見える景色が変わるさまを撮影したり再現したりする」という程度の意味です。
今日は、自作ライトフィールドカメラ撮影画像をライトフィールド印刷してみよう!?でシミュレーションを使って確認してみた、薄層(多層)的・CT的なテクニックで3Dな世界を通常プリンタで表現するライトフィールド印刷を、実際に試してみました。「ライトフィールド」という言葉は一般的ではありませんが、ここでは「観る方向によってどんな色・明るさが見えるか」という程度の意味だと考えておいて下さい。つまり、「観る方向に応じて、見える景色が変わるさまを撮影したり再現したりする」という程度の意味です。

 まずは、上右図のような多視点ライトフィールド撮影をしてみます。この例では、作業の簡単のために(つまりは手を抜くために)、3×3=9位置での撮影を行います。そして、これを試しにCT的に2層に分解処理すると、右図のようになります。それを(少しの距離をおいて)2枚重ねにした上で、方向を変えつつ眺めると下に貼り付けた動画のようになります。プリント物の重ね方が大雑把だったり、ライトフィールド撮影が3x3位置の大雑把なものだったりすることを考えれば、その割には立体感が感じられる面白い効果があるように思えます。
まずは、上右図のような多視点ライトフィールド撮影をしてみます。この例では、作業の簡単のために(つまりは手を抜くために)、3×3=9位置での撮影を行います。そして、これを試しにCT的に2層に分解処理すると、右図のようになります。それを(少しの距離をおいて)2枚重ねにした上で、方向を変えつつ眺めると下に貼り付けた動画のようになります。プリント物の重ね方が大雑把だったり、ライトフィールド撮影が3x3位置の大雑把なものだったりすることを考えれば、その割には立体感が感じられる面白い効果があるように思えます。
実はこの印刷は、2010年くらい前の研究報告をベースにして、今年ローンチされたサービスを参考に遊んでみたものです。スマホが多視点(ライトフィールド)撮影機能を備え、コンビニプリントがこんな立体プリント機能を備え、あるいは、スマホ画面が立体表示機能を備える…のももう1,2年の間かもしれません。



2017-01-14[n年前へ]
■ライトフィールドプリント最適化のためのBlenderシミュレーション その1
いくつもの視点から見た映像から視点変化に応じた見え方を再現するライトフィールド・プリント(インテグラル・フォトグラフィー)を作るために、Blender を使った透明シートへの印刷シミュレーションをしながら、効率的な印刷方法に挑戦してみた。
どんな場合でも汎用的に使うことができる一般的な画像に対して、視点変化に応じた見え方を再現しようとすると、偏光素子を重ねるなど特殊な方法を使うのでなければ、視野を制限するマスク(アパーチャ)に相当する層を上にプリントした上で、視野変化に応じて見える光(色)をさらにその下にプリントすることになりそうだが、そうすると、次の問題が生じる。変角解像度を両立させるためにはマスク(アパーチャ)を小さくしたくなるが、そうすると画像が暗くなる。
この問題に対して最適解を出そうとすると、マスクの口径(アパーチャー)が持つ周波数特性を、視点変化に対する見え方変化の周波数特性と一致させたくなる。つまり、もしも、視点が変化しても見え方の変化が小さい方向があれば、その方向に対してはマスクの口径(アパーチャー)を大きくし(周波数特性を鈍くし)、視点変化に対して見え方が敏感に変わる方向があれば、その方向に対しての口径を狭くしたくなる。つまり、高周波が鈍ることを防ぎたくなる。
というわけで、ライトフィールドプリントの上面に配置したマスク(アパーチャ−)形状を、視点変化に対する見え方の変化(ライトフィールド勾配)に連動した方向性を持つ楕円形状にした画像生成をするPythonコードを書いてみた。そして、スタンフォードの The (New) Stanford Light Field Archiveをサンプル画像として使い、Blenderでライトフィールドプリントのシミュレーションをしてみたのが下の動画だ。
眺めてみると、マスクサイズを固定とした範囲では、明度と変角解像度という相反する項目の両立が改善したような気もするが、空間方向変化(空間解像度)と連成した処理になっていないこともあり、まだまだ修正すべき項目が多い。…というわけで、次は、変角解像度と空間解像度の最適化を考えてみることにしよう。
2017-01-29[n年前へ]
■「手持ちスマホ撮影動画からの超巨大開口レンズ撮影」に挑戦してみよう!?
かつて、スマホに搭載されているカメラのレンズはとても小さく、綺麗なボケとは無縁の存在でした。しかし、今や最新のスマホには特殊処理によるボケ生成機能などが備えられています。カメラレンズの光学開口径が小さくとも、たとえば2眼カメラなどを備えて距離情報を取得して、距離情報などからボケを人工的に合成するといった仕組みです。
 そんな最新スマホを持たずとも、大レンズのボケ味を手に入れるために、「手持ちスマホ撮影動画からの超巨大開口レンズ撮影」に挑戦してみました。スマホ動画から巨大開口レンズ撮影の手順はとても簡単、まずは目の前の風景にスマホを向けて・なるべくスマホが平面上を動くように意識しながら(スマホを動かしつつ)動画撮影します。そして、動画の各コマから画像ファイル群を生成し、それぞれの画像が撮影された位置や方向にもとづいて撮影された光情報を加算合成する、というものになります。
そんな最新スマホを持たずとも、大レンズのボケ味を手に入れるために、「手持ちスマホ撮影動画からの超巨大開口レンズ撮影」に挑戦してみました。スマホ動画から巨大開口レンズ撮影の手順はとても簡単、まずは目の前の風景にスマホを向けて・なるべくスマホが平面上を動くように意識しながら(スマホを動かしつつ)動画撮影します。そして、動画の各コマから画像ファイル群を生成し、それぞれの画像が撮影された位置や方向にもとづいて撮影された光情報を加算合成する、というものになります。
細かい手順は、スマホ撮影動画(の展開画像をもとに) Bundler: Structure from Motion (SfM) から出力された刻々のカメラ位置・方向や特徴点情報ファイル(bundler.out)を読み込み、それらのカメラ情報にもとづいて、刻々の撮影画像をレンズ開口面に沿った(同じ方向を向く平行カメラが存在していた場合の)光線画像を位置・角度ズレを踏まえて重ねることで、任意のピント位置に焦点を合わせた超巨大開口レンズ撮影画像を生成する…というものです。
試しに、iPhoneを約1.5m×1.0mの範囲で動かしつつ動画撮影し、つまり、レンズ直径約1.5mに相当する範囲で動かしつつ動画撮影し、その画像群から開口合成により超巨大カメラの撮影画像を作り出してみた結果が右上の画像です。
右上画像を眺めてみても、良好なボケ味どころか、全くピントが合っていない画像にしか見えません。直径が1mを超える開口を持つカメラレンズとなると焦点深度もとても浅くなるのでピントがなかなか合わない…というわけでなく、手持ち撮影動画からのカメラ位置・方向精度が低いせいか、単一カメラに平行合成した後のズレが大きいようです。
ちなみに、試しに各画像を(撮影方向による傾きを補正しつつ)位置毎に並べてみると、下の画像のようになります。動画撮影からのカメラ位置推定精度が果たして不十分なのかどうか、次は撮影カメラ位置を精度良く知る事ができる撮影治具でも作り、また再挑戦してみたいと思います。
上記処理のコード手順、Python/OpenCVで書いたコード処理手順は、bundler.outからカメラ位置・方向・焦点距離や歪みパラメータを読み込み、cv2.initUndistortRectifyMapにカメラ情報を渡して、各撮影画像の向き補正用のホモグラフィーマップを作成してremapで変換した後に、各撮影画像を加算合成するという手順です。

Bundlerの出力ファイルを読み込んでライトフィールド合成を行うOpenCV/Pythonコード、まだまだ間違い含まれているような気もしますが、とりあえずここに貼り付けておくことにします。
import cv2
import numpy as np
from matplotlib import pyplot as plt
from PIL import Image
import math
%matplotlib inline
class camera:
def __init__(self):
self.f = 1.0
self.k1 = 0.0
self.k2 = 0.0
self.R = [[0.0,0.0,0.0],[0.0,0.0,0.0],[0.0,0.0,0.0]]
self.T = [0.0,0.0,0.0]
def readBundlerOut( filePath ):
f = open(filePath, 'r')
list = f.readlines()
f.close()
numberOfCameras = int((list[1].split())[0])
cameras = []
for i in range(numberOfCameras):
aCamera = camera()
fk1k2 = [float(j) for j in list[5*i+2].split()]
aCamera.f = fk1k2[0]
aCamera.k1 = fk1k2[1]
aCamera.k2 = fk1k2[2]
rot = []
for j in range(1,4):
rot.append( [float(k) for k in list[ 5*i+2+j ].split()] )
aCamera.R = rot
aCamera.T = [float(k) for k in list[ 5*i+2+4 ].split()]
cameras.append(aCamera)
return cameras
def readImageList( listPath, imageDirPath ):
f = open(listPath, 'r')
list = f.readlines()
list = [ i.rstrip() for i in list ]
f.close()
list = [imageDirPath+fileName for fileName in list]
return list
class lightField:
def __init__(self):
self.w = 2000
self.h = 2000
def loadImageListAndMakeLightField( self,
imagePathList, cameraList, workList, scaleA ):
self.cimg = np.zeros((self.h, self.w,3), dtype=np.uint8)
sum = 1.0
for i in workList:
img = cv2.imread( imagePathList[i], cv2.IMREAD_COLOR )
h, w = img.shape[:2]
imageHeight = img.shape[0]
imageWidth = img.shape[1]
focalLength = cameraList[i].f
principalPointX = 0.500000
principalPointY = 0.500000
distCoef = np.array([ 0.0, 0.0, 0.0, 0.0, 0.0 ])
cameraMatrix = np.array([
[focalLength,
0.0,
imageWidth * principalPointX],
[0.0,
focalLength,
imageHeight * principalPointY],
[0.0, 0.0, 1.0]
])
newCameraMatrix, roi = cv2.getOptimalNewCameraMatrix(
cameraMatrix,
distCoef,
(img.shape[1], img.shape[0]),1,
(img.shape[1], img.shape[0]) )
rotMatrix = np.array( cameraList[i].R )
map = cv2.initUndistortRectifyMap(
newCameraMatrix,
distCoef,
rotMatrix,
newCameraMatrix,
(img.shape[1], img.shape[0]),
cv2.CV_32FC1)
undistortedAndRotatedImg = cv2.remap( img,
map[0], map[1],
cv2.INTER_LINEAR )
scale = 1.0
pt3 = np.array(cameraList[i].T) - np.array(cameraList[0].T)
x = ( self.w/2.0 - pt3[0] * scale * scaleA )
y = ( self.h/2.0 - pt3[1] * scale * scaleA )
pts1 = np.float32( [[0, 0],
[w, 0],
[w, h],
[0, h]])
pts2 = np.float32( [[x, y],
[x + w*scale, y],
[x + w*scale, y + h*scale],
[x, y + h*scale]] )
M = cv2.getPerspectiveTransform( pts1, pts2 )
img2 = cv2.warpPerspective(
undistortedAndRotatedImg, M, (self.w, self.h) )
sum = sum + 1.0
self.cimg = cv2.addWeighted(
self.cimg, (sum-1) / sum,
img2, (1.0) / sum, 0)
def showImage(self):
plt.figure( figsize=(14,14) )
plt.imshow( np.array(self.cimg2) )
plt.autoscale( False )

