2001-04-29[n年前へ]
■ファイト!縦文字文化 
縦と横の解像度を考えよう
今年も去年に引き続き英語研修を受けている。といっても、去年は毎日十五分の英語研修だったが、今年は週二日のものを二種類受けている。何事も、「一番弱いところを強くするのが一番」というわけで、それが私の場合は英語であるわけだ。いや、もちろん弱いところは数え切れないほどあるのだが、英語はもうどうしようもないくらいダメなのである。
その英語研修を受ける中で、本当に実感するのが「頭の中でも英語で考えないとキツイ」ということである。頭の中で日本語で考えてから英語で喋ろうとすると、その「日本語→英語変換」のオーバーヘッドはすさまじくて、とても会話にならないのである。もちろん、当然その逆もしかりで「英語→日本語変換」なんかもやっていたら、あっというまに相手の喋るスピードについていけず、「ここはどこ?私はだれ?」状態になってしまう。
もちろん、「頭の中で英語で考えられる位なら、そもそも苦労はせんのじゃぁ!」と叫びたくなることもしばしばあるわけで、実際のところ私にはどうしたら良いのか全然わからないのである。「頭の中に言いたいことは沢山あるけど、それを伝えられない状態」と「頭の中でたいしてものを考えることができない、それを伝えられる状態」とどっちかを選べと言われても困ってしまう。残念ながら、「英語で頭の中でビュンビュンと考えて、それが口からペラペラとでてくる」状態は私には遠い夢物語のようなのである。
こんな苦労は、日本語人生一本やりだった私が英語を使う場合にはどうしても避けられない話なのであるが、そんな「私の苦労」と似たような話はコンピュータの世界にも実はある。例えば、「今日の必ずトクする一言」でもよく登場する「Windowsの日本語化のオーバーヘッドに関する一連の話」などがそうである。超漢字あたりであれば話は別なのかもしれないが、Windowsに限らずどんなOSであっても英語だけを使うときと、日本語のような言語を使うときではスピードが全くと言って良いほど違ってしまう。
例えば、英語版のWindowsであれば最新型のPCでなくてもサクサク動くのであるが、これが日本語版のWindowsともなると、最新型のPCでなければカタツムリのようなスピードに変わってしまうのである。最新型のWindowsやMacOS***の推奨マシンスペックは○×○×です、とOSメーカーが言ったところで、それは英語圏での話で日本語人生の私のようなものにはそれは当てはまらないのだ。わずか100文字ほどのアルファベットですむ英語の場合と、約七千字ほどもある日本語を使う場合とでは文字・フォント処理のスピードが違ってしまうのは当たり前の話である。
ところで、英語と日本語をコンピューターなどで扱う時の大変さというものは文字数だけの話なのだろうか?数が多いから大変なのは当たり前なのだが、それだけではないのではないだろうか。単に文字数が多いというだけではなくて、一つの文字当たりの情報量も日本語の方が遙かに多いと思うのである。例えば、アルファベットの中でも複雑な形をしている"M"と、日本語というか漢字の中でも結構複雑な形をしている「廳」を比べてみれば一目瞭然だろう。"M"よりも、「廳」の方がずっと複雑な形状をしている。
漢字の文字数が多いということは、そのたくさんある文字を区別するためにも漢字という文字の形状自体が複雑にならざるをえないわけで、それはすなわち漢字一文字の情報量はアルファベット一文字の情報量よりも遥かに多いということだ。ということは、
- 一文字辺りの情報量が多くて
- しかも文字数が多い
しかし、「PC内部での処理も大変ではあるが、それを外部に出すときも大変だろう」というのが今回の話のテーマである。モニタやプリンタに出力する時の大変さも英語と日本語では大違いで、しかも英語文化で考えると見えない落とし穴があるのではないだろうか、という話である。
まず、文字を表示するスペースというのは大体決まっている。そんな限られた同じスペースの中に、一文字辺りの情報量が少ないアルファベットと多い漢字を同じように詰め込めるだろうか?先ほどの"M"と「廳」を縮小して10pt程度にしてみると、その答えはすぐにわかる。アルファベットの"M"の方はちゃんと読めるとは思うが、漢字の「廳」の方がちゃんと識別できる環境の人がいるだろうか?PCの画面に表示されている「廳」はずいぶんと省略されたてしまっていたり、あるいは潰れてしまっていたりするはずである。
つまりは、PCの内部でも漢字のような文字を扱うのは大変であるが、それを外部へ表示したりするのも実際問題大変なのである。英語圏のアルファベット文化から考えれば、10ptなんて大きくて読みやすいと思うのかもしれないが、漢字などを考えると今のモニタの解像度では10ptでも小さすぎるのである。逆にいえば、アルファベットなどを表示する時に比べて漢字などの文字を表示する時には、遥かに高い解像度のモニタが必要とされるのである。PC自体の能力だけではなくて、モニタなどの出力機器も遥かに高い能力が必要とされるわけだ。
もちろん、それは漢字だけの話ではない。世界中の文字で当てはまるハズの話である。試しに、
- 世界の文字 (http://www.nacos.com/moji/)
 |  |  |
 |  |  |
アラビア文字あたりはラテン文字であるアルファベットと同じ程度の複雑さであるが、その他の文字はやはり遥かにアルファベットよりも複雑な形状をしている。「この中の半分くらいは使われていない文字じゃねぇーか!」という声も聞こえてきそうな気もするが、そんな小さいことを気にしてはいけない、とにかくアルファベットは色々ある文字の中でも単純な形状をしていて、漢字は複雑な形状をしているのである。
次に、それぞれの文字画像の複雑さの特徴を眺めるために、それぞれ二次元フーリエ変換をかけて、周波数空間に変換してみたものを示してみることにしよう。まずは、漢字の例を示して図の見方を説明してみたい。
 | 図の横・縦方向が実際の文字の横・縦方向に対応し、図の中で中央から外周方向に向かって低周波から高周波の成分の量を示している。強さは 小 ← 赤 黄 黄緑 青 紫 → 大の順番になっている。 たとえば、この漢字の例だと |
上の説明に書いたように、こんな風に文字画像を周波数空間に変換すると、「漢字は縦と横の線が多い」ということがよくわかる。しかも、
の時に調べたように、漢字は「縦方向に周波数成分が多い」、すなわち言い換えれば「横方向の線が多い」こともわかるのである。 さて、世界の文字六種に戻って、それぞれを周波数空間に変換して並べてみると、こんな感じになる。
 |  |  |
 |  |  |
こうして六種の文字種を周波数空間に変換して眺めてみると、色々なことが判る。例えば、
- アラビア文字はほとんど高周波を含まない
- ヒエログラフは比較的高周波が少なく、方向性も持たない
- 漢字に含まれる高周波成分はほとんどが縦・横方向のみであり、その中でも「縦方向に周波数成分が多い」、すなわち言い換えれば「横方向の線が多い」
- アルファベットは低周波がメインであり、縦横では横方向の方が高周波を含んでいる、すなわち縦の線が多い
- マヤ文字は一番高周波まで含んでおり、比較的方向性も少ない
- ロンゴロンゴ文字はアラビア文字よりも高周波が多いが、それでも比較的低周波メインであり、方向性もない
もちろん、ラテン文字が比較的高周波が少ないからといって今の表示装置で十分だというわけではなくて、ラテン文字でもより高解像度のディスプレイが必要とされている。例えば、液晶画面などで文字を多量に読むことを想定している電子ブックなどの用途のためには、
で調べたMicrosoftの「ClearType」などの技術がある。これは液晶のRGBの画素の配列が横方向に並んでいることを利用して、横方向の解像度を高める技術である。ということは、こういう技術は横方向の高周波成分が多いラテン文字などでは効果が大きく、またラテン文字自体が比較的高周波成分が少ないために、こういう技術を使えば必要十分ということになるのかもしれない。しかし、日本語(漢字)のようなもともと高周波成分が多くしかもそれが縦方向に多い、というようなものでは効果は比較的少ないことが考えられる。もちろん、それは液晶というデバイスの特徴によるもので仕方のない部分もあるのだが、もしかしたらもしかしたら日本語のような縦方向の高周波を再現しなければならない言語のことを意識していないせいかもしれない。
こんなことは液晶などのモニタだけではなくて、一般的なプリンタもそうだ。例えば、インクジェットプリンタではエプソンのPM-900Cの仕様などを眺めてみても、標準で720×720dpiで、高画質モードでは1440×720dpiとなっている。それはレーザービームプリンタなどでも同じで、リコーのプリンター大百科からウルトラスムージングテクノロジーを見てみても、やはり横方向の解像度のみを高めて2400dpi×600dpiとなっている。やはり、プリンタなどの印字装置でも横方向の解像度を高めようとはするが、縦方向の解像度は低いままにしているのである。もちろん、縦方向の解像度を高くすると印字速度が遅くなってしまうという、プリンタの特性があるにしても、やはり日本語を印字するためには不利な設定となっているのである。日本人としては、解像度表示は縦方向を重視するべきで、横方向の解像度表示にダマされるべきではないのである。高解像度2400dpiなんて言われても、「ヘヘン、オレは縦文字文化の日本人だから関係ないんだもんね」くらいは言って欲しいわけである。
実際のところ、せっかく日本語(漢字)を使うのだから、日本語の特性に応じたPCやモニタやプリンタがあっても良いのになぁ、と思う。いや、というより日本語の特性をもっと理解するところから始めなければならないのかもしれない。そうだ、私はまずは日本語の勉強から始めるべきなのだ。英語の勉強をしている場合ではないし、頭の中で英語で考えていたりすると、縦文字文化に合った発想ができなくなってしまうに違いないのである。って、英語学習から逃げてるだけだったりして…
あぁ、しまったぁ。今回はホントに真面目な話になってしまったぞ、と。しかも、まるで国粋主義者みたいだし。
2005-07-05[n年前へ]
■スクロールバーに見る「未来の予感」 その3

 スクロールバーに見る「未来の予感」 その2に書いたように、『スクロールバー類はその言語の「上手」に位置するのが自然である一方で、同時に「スクロールバー」類は本文よりも「利き手側」に位置する方が自然』に思えます。
スクロールバーに見る「未来の予感」 その2に書いたように、『スクロールバー類はその言語の「上手」に位置するのが自然である一方で、同時に「スクロールバー」類は本文よりも「利き手側」に位置する方が自然』に思えます。
そんな「自然」を実感するのが、アラビア言語系のページをInternet Explorerで眺めているときの「不自然」さです。右の二つの画像はnakama yukie"をGoogle Japanで検索をかけた結果と、同じくGoogle Arabicで検索をかけた結果です。アラビア語表示のGoogleをInternet Explorerで眺めていると、スクロールバーが本文左側に位置してしまいます。その結果、不自然な操作感になります。もちろん、Tablet PCを使っていたりすると、スクロールバーを操作しているときには(右腕に遮られて)全く本文が見えなくなってしまいます。本文をスクロールしたいのに、その肝心の本文が見えなくなってしまうのです。まさに、本末転倒です。
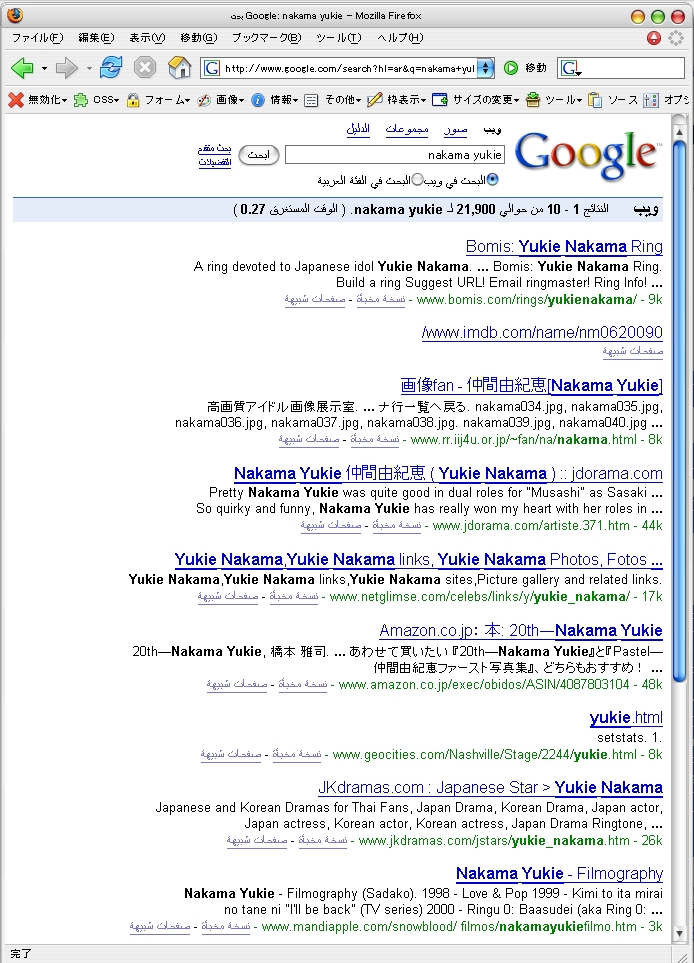
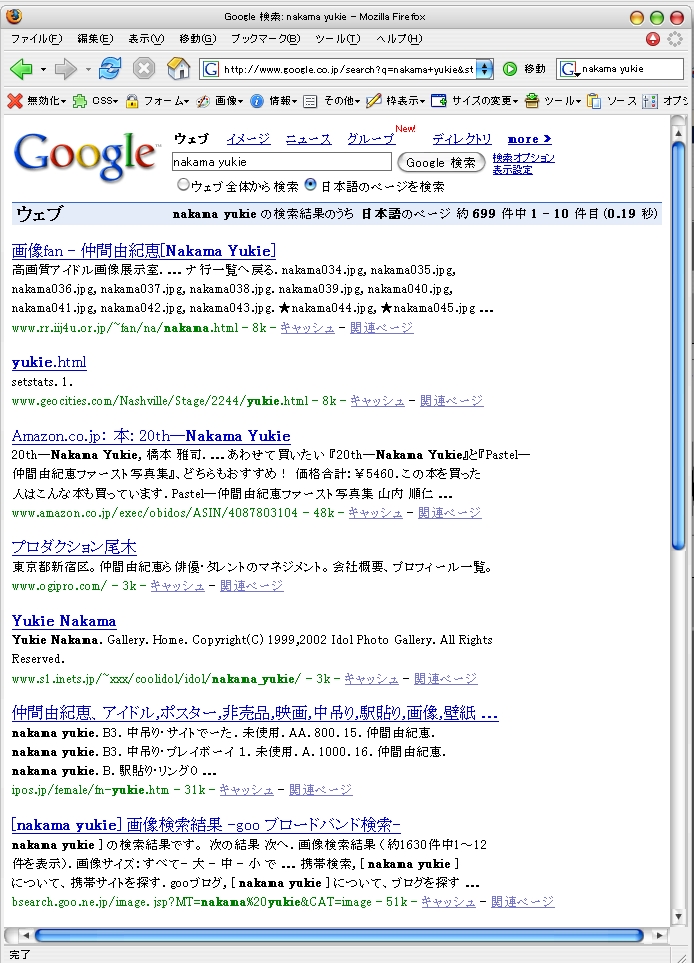 一方、Fire foxではそんな風にはならないので(右の二枚のスクリーンショット参照)、アラビア語圏のページをTablet PCで眺めるときには、Fire foxを使うようになりました。アラビア語圏の右利きの人はTablet PC上でFire foxを使うと、とても気持ちよい操作感になりそうです。『スクロールバー類はその言語の「上手」に位置するのが自然である一方で、同時に「スクロールバー」類は本文よりも「利き手側」に位置する』わけですから。同じように、左利きの日本人がこんなテクニックでも使って、右側にスクロールバーを持って行ったInternet Explorerを使っていたりすると結構気持ちが良いのかもしれません。残念ながら私自身は右利きなので、その気持ち良さを実感することはできませんが…。
一方、Fire foxではそんな風にはならないので(右の二枚のスクリーンショット参照)、アラビア語圏のページをTablet PCで眺めるときには、Fire foxを使うようになりました。アラビア語圏の右利きの人はTablet PC上でFire foxを使うと、とても気持ちよい操作感になりそうです。『スクロールバー類はその言語の「上手」に位置するのが自然である一方で、同時に「スクロールバー」類は本文よりも「利き手側」に位置する』わけですから。同じように、左利きの日本人がこんなテクニックでも使って、右側にスクロールバーを持って行ったInternet Explorerを使っていたりすると結構気持ちが良いのかもしれません。残念ながら私自身は右利きなので、その気持ち良さを実感することはできませんが…。
2014-05-18[n年前へ]
■「未知数”x”の語源はアラビア語という面白話」はデマの可能性が濃厚です!?
![]() 「未知数”x”の語源はアラビア語という面白話」はデマの可能性が濃厚です!? を書きました。
「未知数”x”の語源はアラビア語という面白話」はデマの可能性が濃厚です!? を書きました。
「方程式で未知数を”x”として表すことが一般的になったのはアラビア語に由来する」という話があります。xやyあるいはzといった文字で未知数を表し、a,b,c…といった文字で既知の値を表すのは、17世紀に活躍したフランスの学者 デカルト が使い、その結果広まったとされる流儀です。この流儀の背景には、8世紀から15世紀にかけて盛んだったイスラム数学が反映されているという「へぇ〜。なるほど〜」と感じさせられる説明です。…この話は、さまざまな興味深いトークを開催しているTEDでもTerry Moore: Why is ‘x’ the unknown?として行われ、現在では非常に広まっています。