1999-11-20[n年前へ]
■バナー画像のエントロピー 
がんばれ、JPEG
前回、
で「バナー画像中の文字数とファイルサイズ」に注目し、「文字情報密度」というものについて考えてみた。情報密度を考えるのならば、で考えたエントロピーについても計算してみなければならないだろう。そこで、今回は前回登場したバナー画像達のエントロピーを計算してみることにした。それにより、情報圧縮度について考えてみることにするのだ。
そうそう、今回も「本ページは(変な解説付きの)リンクページであります」ということにしておく。他WEBのバナー画像を沢山貼っているが、それはこのページが「リンクページ」であるからだ。
エントロピーを計算し、画像の圧縮度を調べる際に、今回はファイル先頭の400Byteにのみ注目した。ファイル全体で計算するのは面倒だったからである。各バナー画像でファイルサイズが異なるからだ。そこで、全て先頭400Byteに揃えてみた。
行う作業は以下のようになる。
まずは、画像ファイルの「先頭400Byteの可視化画像」を作成する。これは、各ファイル中の各Byteが8bitグレイ画像であると考えて、可視化したものである。以前書いたように、「てんでばらばらに見えるものは冗長性が低く、逆に同じ色が続くようなものは冗長性が高い」のである。もし、同じ色が続くとしたならば、「また、この色かい。どうせ、次もこの色なんだろ。」となってしまう。次の色の想像がつく、ということはすなわち、情報としては新鮮みのないものとなる。つまり、情報量が少ないのである。その逆に、情報量の多いものは、てんでばらばらで次の色(データ)の予想がつきづらいもの、となるわけである。まずは、そのてんでばらばら具合を「先頭400Byteの可視化画像」で確認する。
次に、てんでばらばら具合をヒストグラムで確認する。各Byteが0から255のどの値をとることが多いかを調べるのである。てんでばらばらであれば、どの値をとる確率もほぼ同じであり、フラットなヒストグラムになるはずである。逆に、ヒストグラム上である値に偏っていれば、値の予想がつきやすく、情報量が少ないということになるわけだ。
最後に、各Byteのデータを「8元無記憶情報源モデル」に基づいて計算したエントロピーを計算した。各Byteのエントロピー、すなわち、平均情報量は最大で8となる。当たり前である。1Byteは8bitであるから、最大限有効に使いきれば、情報量は8bitになる。
それでは、青い「hirax.net できるかな?」バナーを例にして見てみる。
| 文字情報密度 | ファイルサイズ(Bytes) | 画像 | 先頭800Byteの可視化画像 | ヒストグラム | エントロピー(bits/Byte) |
| 35 | 662 | 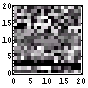 |  | 7.1 |
この画像ファイルはトータルで662Bytesであるが、その先頭400Bytesの可視化画像はけっこうばらばらである。それは、ヒストグラムをみても確認できる。少し、0近傍が突出しているが、それを除けば、かなり均等である。そして、エントロピー、すなわち、1Byte当たりの情報量は7.1bitである。満点で8bitであるから、7.1bitはなかなかのモノだろう。
それでは、前回登場したバナー画像達に、同じ作業をかけてみる。
| 文字情報密度 | ファイルサイズ(Bytes) | 画像 | 先頭400Byteの可視化画像 | ヒストグラム | エントロピー(bits/Byte) |
| 31 | 874 |  |  | 6.7 | |
| 34 | 648 | 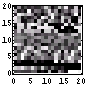 |  | 7.2 | |
| 35 | 662 | | | 7.1 | |
| 40 | 763 |  | 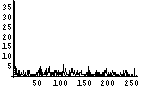 | 7.1 | |
| 44 | 1003 |  |  | 7.1 | |
| 54 | 750 |  | 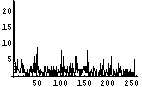 | 7.1 | |
| 58 | 864 |  |  | 6.6 | |
| 112 | 2472 | 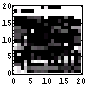 |  | 3.8 | |
| 124 | 2348 | 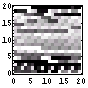 |  | 7.0 | |
| 155 | 465 |  |  | 7.3 | |
| 223 | 3116 |  | 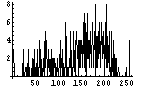 | 7.0 | |
| 294 | 881 | 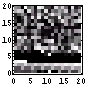 |  | 6.6 |
IntenetExplorer、RealPlayerといった、ヒストグラム上で突出している値がある画像はエントロピーが少ない。すなわち、平均情報量が少ない。大体、6bit台である。gooは0近傍の値が突出しているのが足を引っ張り、6.6bitとなっている。これらは、1Byteの8bit中の1bit強が無駄となっているわけである。
最高点はMacの7.3bitである。8bit中で7.3bitの情報量を持っているのである。逆に言えば、0.7bitは無駄ということになる。しかし、8bit中7.3bit使い切っているのはなかなかのものである。
それ以外は大体7bit台で拮抗している。しかし、それはいずれもGIF画像である。そう、唯一のJPEG画像である「今日の必ずトクする一言」が3.8bitと低い情報量であるのだ。しかし、これには、いろいろな理由があると思われる。例えば、ファイル全体ではなく先頭のみを見ているため、JPEGのヘッダー部分が入ってしまい、冗長性が高くなってしまっている、とかである。全体でなく、部分で評価しているのは非常にマズイだろう。また、GIFが情報圧縮していることもあるだろう。そのため、JPEG陣営にはかなり不利であったと思われる。
そうそう、今回は情報圧縮度にだけ注目したから、JPEGに不利な結果になった。けれど、他のいろいろな理由を挙げれば、GIFは使いたくないという気持ちもあるのだけれどね。けど、便利なんだよね。
1999-12-04[n年前へ]
■WEBの世界の「力の法則」
「ReadMe!JAPAN」と「日記猿人」に見るWEBアクセス数分布
以前、
の中で書いたように、「Webの成長のダイナミクスとトポロジは,物理学の世界のPower(累乗)Lawとして知られている法則に従っている」という面白い話が世の中にはある。これは、「ごく少数のWEBサイトへのアクセス、あるいはリンクが他を圧倒する程の割合を示す。」ということである。「インターネットのほとんどのアクセスというものは、ごく少数の特定のサイトへのものである。」ということだ。宇多田ヒカルの売り上げが演歌の総売上をはるかに超えるという話とよく似ている。実社会でもそういうことは実に多い。どうも、マイナー趣味である私には、Power(累乗) Lawというのはいま一つ面白くない話ではあるが、
- InternetEcologies
- http://www.parc.xerox.com/spl/groups/dynamics/www/internetecologies.html
- Paperson small-world networks
- http://www.ncrg.aston.ac.uk/~vicenter/smallworld.html
まずは、考えるためのデータを採取してることにした。欲しいデータは色々なWEBサイトへのアクセス数である。もちろん、自分のWEBサイトへのアクセスではないのだから、何らかの公開データを探さなければならない。
そこで、ReadMe!Japan(http://readmej.com/)と日記猿人(http://wafu.netgate.net/ne/)という二つのランキングシステムを用いてみた。ReadMe!Japanは日本語の「読み物」を主体としたWEBランキングである。また、日記猿人は名前の通り「日記」をターゲットとしたWEBランキングである。
一見、同じように見えるReadMe!Japanと日記猿人のランキングであるが、かなり違ったシステムである。以下に、Readme!Japanと日記猿人のランキングシステムを示してみる。
- Readme!Japan 登録したWEBページに、一日の間にアクセスしたIPアドレスの数。
- 日記猿人 「投票」ボタンを押した人(ブラウザー)の数、一日の間に一人の人(ブラウザー)が同一の日記に対して複数回の投票は行うことが出来ない。
一方、Readme!JapanはIPアドレスベースであるから、同一のProxyなどを経由したアクセスの場合、何人からアクセスがあろうと1pointである。しかし、読者に「投票ボタンを押す」というような作業は要求されない。
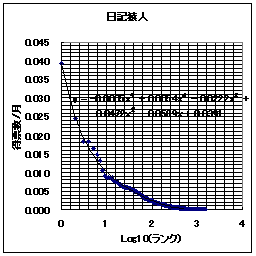
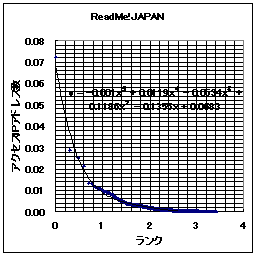
それでは、日記猿人とReadMe!JAPANの得票ランキングの例を示してみる。横軸はランク(順位)であり、縦軸が得票数である。ここでは縦軸・横軸共に線形軸を用いている。
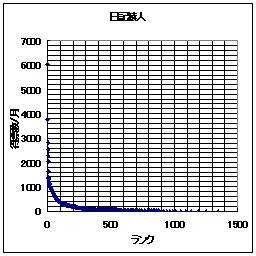 | 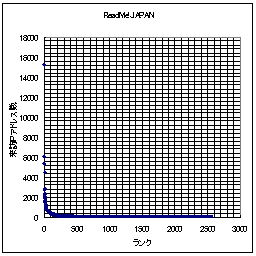 |
なお、 Readme!Japanは11/30日のものであり、日記猿人は(ほぼ)11月分の得票数分である。
このグラフを眺めてみると、日記猿人とReadMe!JAPAN共によく似ている。なるほど、少しランクが下がっただけで、急激に得票数が少なくなっている。もう、縦軸で言うならば下に張りついてしまっている。「ごく少数のWEBサイトへのアクセス、あるいはリンクが他を圧倒する程の割合を示す。」という「WEBの世界の力(累乗)の法則」は日記猿人とReadMe!JAPANでも当てはまるようである。
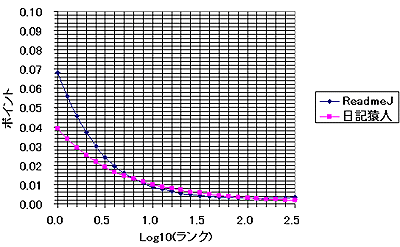
さて、ここまでランクに対して得票数が変化するとなると、グラフの軸は線形軸でなくて対数軸の方が良いだろう。そこで、グラフの軸を対数軸に変えたものを以下に示す。
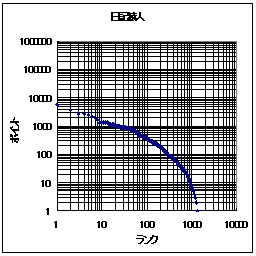 |  |
こうすると、日記猿人とReadMe!JAPANのどちらも、
- 上位のランク(例えば、1位から1000位程度まで)では傾きがほぼ1である。すなわち、ランクが一桁下がると、アクセス数も一桁下がる。
また、ReadMe!JAPANでは、ランクが極めて大きい所では得票数が0に近い。おそらく、その影響と考えられるが、ランクと得票数の関係が直線でなくなっている。
それと同じことは日記猿人でも言えるだろう、ただし、「ランクとポイントの関係が直線でなくなる」のがReadMe!JAPANよりも早いような気がする。しかし、それは誤差かもしれない。参加数もかなり異なっているので、誤差の可能性が高いと思われる。
さて、これまでは日記猿人とReadMe!JAPANのランキングの数字を直接用いてきたわけである。しかし、得票数の全く違うものをそのまま比較してもしょうがない。ある程度条件をそろえた上で比較をすべきであろう。そこで、縦軸を正規化して比較をしてみることにした。得票数の合計が1であるような単位に変換してみるのである。
ここで、横軸はランクのLog_10を用いている。本来、ランク(順位)も何らかの正規化の変換をすべきであろうが、今回はやり忘れた。きっと、頭が疲れているせいである。
また、グラフを見ればわかると思うが、それぞれについて近似曲線を計算している。
 |  |
次に、ここで得られた「ランクとポイントの関係」を示す近似関数
- ReadMe!JAPAN y = -0.001x^5 + 0.0119x^4 - 0.0534x^3 + 0.1186x^2 - 0.1355x+ 0.0683
- 日記猿人 y = -0.0005x^5 + 0.0054x^4 - 0.0222x^3 + 0.0472x^2 - 0.0589x+ 0.0391
 |
R eadMe!JAPANでも日記猿人でも横軸が2以上(すなわち100位以下)の場所などでは、ほとんどポイントはゼロみたいなものである。すなわち、100位より下のWEBのアクセス(本WEBへのアクセスも含めて)は誤差みたいなものなのだ。何しろ、一位(トップ)のポイントが0.07とか0.04とかなのだ。それは「一位のWEBサイトへのアクセスが全部のサイトへのアクセスの1割弱を占める」ということなのである。20位までのサイトへのアクセスを合計すると全アクセスの50%以上を占めてしまう。これが、恐るべきWEBの世界の"PowerLaw"、すなわち、「力(累乗)の法則」である。
ところで、日記猿人では上位サイト(すなわち、横軸で0に近いところ)での関係式の傾きがReadMe!JAPANよりも小さい。すなわち、上位サイトの得票数が拮抗している。これは一体何故だろうか?
私はこの理由を、
- 日記猿人の読者が割と似ている趣味を持っている
- 日記猿人の参加WEBサイトが似たような内容を持っている
日記猿人の参加WEBサイトが似ており、読者同士が割と似ている趣味を持っていれば(私も含めて)、得票数というのは当然横並びになるだろう。上位サイトにはほとんどの人が見に行き、そしてほとんどの人が「投票」ボタンを押せば、上位サイトはみな同じような得票数を示すことになる、と思うのである。
それは、違う傾向を示すReadMe!JAPANの中でも、読者層も作者も似ている「Fast&First」と「今日の必ずトクする一言」はとても近い得票数を示している、ということがその根拠の一つである。
それに対して、ReadMe!JAPANが比較的広いジャンルの「読み物」が集まっているのでそういう現象が見られないのだろう、と考えるのである。しかも、実際には「読み物」ですらないものも集まっているので、なおさらジャンルとしてはバラけている。だから、「WEBの世界の力(累乗)の法則」を素直に反映していると考えるのである。
私としては、ごく一部のWEBサイトへの集中が生じるのはツマラナイと感じてしまうのであり、「WEBの世界の力(累乗)の法則」はキライである。だからといって、趣味が似た人ばかりというのもツマラナイように思う。うーん、どういうのがツマラナクナイのだろうか?
それはきっと、「色々な趣味の人が色々なWEBへアクセスする」というのが私の好みだ。実現は難しいのだろうけど...いや、そんなことはないか。
1999-12-06[n年前へ]
■立体音感を考える
バーチャルサウンドソフトウェアを作ってみよう
立体感というものには何故か強く心惹かれるものがある。まして、それが人工的な立体感であるならば、なおさらである。それは、画像・映像であっても、音であっても同じだ。色覚なども同様なのだが、人間の感覚というものを人間自身の技術により再現できたりするのが、実に面白い。
何より、自分が実感できるというのが良い。結果を自分で感じることができるというのは、素晴らしいと思う。よくソフト技術者などで、「もう少し目に見えるものが作りたい」という人がいるが、それと同じである。
小・中学校などでも実感できる教材や授業というのがあれば素晴らしいと思う。最近のWEBを眺めていると、そういう先生方のグループも多いようだ。そういう先生は「えらいなぁ」とつくづく思う。今の学校の先生は、そういうことをすればするほど、仕事としては時間単価が下がってしまうのだろう。それでも、そういった先生方は、きっとそういうことは気にしてはいられないのだろう。ホントにエライ。
さて、立体感を実現するソフトであるが、そういった技術には色々なモノがある。音響の立体感の実現を目指す技術に関しても、古くから数多い技術がある。そういったものを追求しているWEBも多々あり、
「今日の必ずトクする一言(http://www.tomoya.com/)」の
- 山本式スーパーバイノーラルコンペンセーターのナゾ(その2、ソースを考える編)
- http://www.bekkoame.ne.jp/~jh6bha/higa9810.html#981013
- 山本式スーパーバイノーラルコンペンセーターのナゾ
- http://www.bekkoame.ne.jp/~jh6bha/higa9810.html#981008
- 山本式バーチャルサウンドシステムのナゾその2(原理解説編)
- http://www.bekkoame.ne.jp/~jh6bha/higa9804.html#980421
- 山本式バーチャルサウンドシステム(PATPEND.)のナゾ
- http://www.bekkoame.ne.jp/~jh6bha/higa9803.html#980307
また、そういったものを実現しようとする製品は昔から掃いて捨てるほどある。最近の製品では、
- ヤマハ、スピーカー間隔0でステレオ音場を実現するLSI
- http://www.watch.impress.co.jp/pc/docs/article/990122/yamaha.htm
- ヤマハ デジタルオーディオ用LSI『YSS901』
- http://www.yamaha.co.jp/news/99012101.html
私も出張などで新幹線などに乗っている際には、E-500などでヘッドホンで音楽を聴いていることが多い。そういう時には、先の「山本式スーパーバイノーラルコンペンセーター」などが欲しくなり、音の立体感などについて色々と考えてしまう。必要に迫られているせいか、立体音感については、私もとても興味を惹かれるのである。
というわけで、「できるかな?」でも立体音響について考えてみたいと思う。といっても、考えるだけでは面白くない。それに「ナントカの考え休むに至り」ともいう。私が考えるだけでは、何にもならないし、しょうがない。色々と実験をして遊んでみたい。
そのために、まずはいくつかの道具を作ってみることにした。
今回、作成するのは、山本式バーチャルサウンドシステムソフトウェア(名付けてYVSSS。略称が長いので、以降YVS3と称することにする。)である。先の「今日の必ずトクする一言(http://www.tomoya.com/)」の一連の話しに出てくるそれである。スピーカーマトリックスの程度を小さくしたものである。
バーチャルサウンドシステムソフトウェアというと仰々しいし、ものすごいソフトウェアに思えるかもしれないが、実はそんな大したモノではない。それどころか、実に簡単なモノである。実際には、Waveファイルを開いて、そのファイルの左チャンネル(L)、右チャンネル(R)に対して、
- R'= R - 1/3L
- L'= L - 1/3R
ここに、今回作成したソフトを置いておく。いつものことであるが、完成度はアルファ版以下である。
使い方を示しておく。まず、下が動作画面である。水平方向にスライダーがあるが、チャンネル同士の演算の係数を決めるものである。左端が0%であり、右端が100%である。
 |
すなわち、スライダーが左端であれば、
- R'= R - 0 L = R
- L'= L- 0 R = L
- R'= R - L
- L'= L- R
Load_Convertボタンを押して、WAVファイルを選択し、変換することができる。その際、オリジナルのファイルは"*.org"という名前で保存される。
さて、このソフトを使って、
- 種ともこのアルバム「感傷」から「はい、チーズ!」
- THE POLICEのLive at the "Omni" Atlanta, Georgia During 1983 U.S.A Tourから"SoLonely"
試聴のやりかたは、Cd2wav32.exeを使い、CDからWAVファイルにする。そして、WaveMixPro(YVS3)を使って、バーチャルサウンドシステム構築する。そして、それをヘッドホーンで試聴するわけだ。適当にチャンネル同士の演算の係数を変化させ、聴いてみた。果たして、立体感は増しているか?
さて、試聴した結果であるが、「うーん。」という感じだ。
係数を大きくすると、まるで「カラオケ製造器」である。ボーカルが消えるだけである。しかも、聴衆が頭の真ん中に居座っているような感じである。つまり、立体感がむしろなくなってしまっている。「何故、オマエらはオレの頭の真ん中で拍手をするのだ」、と言いたくなる。頭が変になりそうである。
かといって、小さいとよく違いがわからない。困ったものである。
さてさて、まだまだ第一回目ではあるが、前途多難の気配であるのが心配なところだ。
2000-02-21[n年前へ]
■「私の心」の円グラフ
私と好みが似てる人 その4
これまで、「できるかな?」では
- 「私と好みが似てる人」 その3- ドメイン一覧とreferer log - (1999.08.29)
- 「私と好みが似てる人」 その2- ログ解析の6ヶ月点検 - (1999.05.03)
- 「私と好みが同じ人」 - analogWindows版用のサブドメイン解析ソフトを作る - (1999.01.24)
前回から半年以上の時間が経ったので、今回も、「私と好みが似てる人」の解析を行ってみたい。今回の着目点は次のようなことである。
HIRAX.NETで記録されるreffer_logはHIRAX.NETへリンクが貼られているサイトのアドレスが記録されている。例えば、
http://umz.pos.to/Link/info.html -> /index.htmlというものであれば、「果テシナク続ク複数ノ零 」(きっと、Think Difficultを読んでいたのだろう。)を読んだ後にHIRAX.NETに訪れた、ということがわかるし、
http://www.hirax.net/index.html -> /dekirukana/moire2/index.htmlであれば、HIRAX.NET内の移動であることがわかる。また、
bookmarks -> /index.htmlであれば、ブックマークを使うことで、HIRAX.NETへ訪れたことが判るわけである。
また、実はリンクもブックマークでもなくて、「単に前にただ読んでいただけ(他のWindowで開かれているサイトでリンクが貼られていた場合など)」というものもたまには記録される。
このようにして、「私と好みが似てる人」達がどんなサイトを読んでいるかがわかるのである。最後に書いたように、reffer_logに記録されるのは、HIRAX.NETへリンクを貼っているサイトだけではないので、訪れる前に読んでいたサイトが(ある程度だであるが)わかるのである。
前回の、
では「HIRAX.NETへリンクを貼っているWEB作者を探る視点」から眺めた。今回は「私と好みが似てる人達がどんなサイトを読んでいるか」という視点から眺めてみたい。そして、「私と好みが似てる人」=「私」と考えて、私の好みを第三者的に考えてみたいのである。 話が変わるように思えるかもしれないが、私は「結果が全て」であると考えている(少なくとも、今の瞬間は)。「心の中で思っていて」も、口に出さなければ「思っていない」のと同じである。「掌の中の答え」は掌を開いてみなければわからない。
だから、他の人が自分に対して抱くイメージとは違う「ホントのオレ」があると主張してもしょうがない、と思うのである。「他の人が自分に対して抱くイメージ」=「ホントのオレ」であると思うのである。もちろん、「他の人が自分に対して抱くイメージ」をどう変えるかは自分次第だ。「掌の中の答え」は自分が決めるのだが、「掌の中の答え」を他の人に見せて、やっと「答え」になるのである。
話が長くなったが、「自分の好みはこうだ」と自分で言うのもなんなので、第三者的に「自分の好み」を探ってみることにしたのである。その材料はHIRAX.NETを読んでいる方(つまり、あなた)の読んでいるサイトである。これを読んでいるあなた自身がリトマス紙なのである。「私の好み」は「あなた自身の好み」でもあるのだ。
というわけで、今月前半のreffer_logよりHIRAX.NET外からリンクされた(あるいは移動してきた)、3276アクセスに対して解析を行った。reffer元を私が読んで、大雑把な分類をしてみた。用いた分類は、
- 読み物
- 検索
- コンピュータ
- 日記
- 雑情報
- エロ
- ニュース
- 画像
- 色
- 音楽
- ランキング
- 科学
- 深津絵里
- 製品情報
- イントラ内サイト
- 自然
- 文学
- ゲーム
例えば、
- 読み物 今日の必ずトクする一言 etc.
- コンピュータ お笑いパソコン日誌 etc.
- 雑情報 Fast & First etc.
 reffer_logのreffer元がHIRAX.NETでない3276アクセスを分類したもの |
なるほど、「読み物(あぁ、なんて大雑把なくくりだ)」が三分の一を占め、以下「情報検索サイト(infoseekなど)」が1/5程を閉めている。そして、コンピュータ情報等だ。なるほど、それが「私の心の中の興味」と言われれば納得するものである。「科学」や「自然」がずいぶんと下位であるのが不思議なところであるが、まぁしょうがない。まぁ、こんなところだろう。
が、問題は次である。何故か、「エロ」サイトが6位にいるのである。これは、「IO= アイオー」ではない。「エロ = えろ=すけべぇ」である。
 reffer_logのreffer元がHIRAX.NETでない3276アクセスを分類したもの |
これは、困った事態である。私としては、「オレはエロサイトよりニュースサイトの方をよく見るぞ!」と主張したいところである。いや、ホントに。しかし、先ほど
他の人が自分に対して抱くイメージとは違う「ホントのオレ」があると主張してもしょうがないと書いた所でもあるし、黙って受け入れなければならないだろう。何か、最近「できるかな?ってあれでしょ。ミニスカートの研究をしているスケベサイトでしょ。」と言われてたりするような気がしてしょうがないのだ… それも、また受け入れなければならないのだろうが…少し、悩んでしまう。
それとも、エロサイトを読んだ後に、心の清涼剤として「できるかな?」を読んでいるのだろうか?なるほど、それならわかる。納得だ。 うん、そういうことで納得しておきたい。
というわけで、先のグラフがが「私=これを読んでいるあなたの心の円グラフ」である。私の悩み=あなたの悩みでもあるはずだ。あなたの心の中には「エロ」が堂々6位に登場しているハズである。あなたの心はニュースより「すけべぇ」が好きなのだ。がんばれ、「私と好みが似てる人」。せめて、「ニュース」の方が上位に来るようにしてくれ…
2000-05-21[n年前へ]
■hixの歩き方
全文検索をしてみよう
hirax.netのコンテンツ、といっても今のところ「できるかな?」しかない、も数が増えてきた。ページ数は増えてきたが、ごく短いページがほとんどである。というわけで、残念ながら内容はたいしてないのが残念である。しかし、内容がなくてもページ数が増えてくると、どの記事をどこに書いたか判らなくなる。あるいは、読むほうも同じだろう。「今日の必ずトクする一言」の「本ページのメニューシステムと逆リンクのナゾ」には
章があまりページに細分化されていない方がむしろ検索効率が良い。と喝破しているがその通りである。私もトップのメニューだけは「ウナギの寝床メニュー(copyrightwww.tomoya.com)」を採用しているが、各コンテンツはそれぞれディレクトリを作って細分化させてしまっている。画像ファイルやバックデータとしてのデータファイルも使用する場合があるため、どうしてもそうなってしまう。
もちろん、infoseekなどにも登録はしてあるから、ある程度の内容を検索することはできるのだが、残念ながらそれほど詳しい検索はできない。自分でも不便に思っていたこともあるし、この「できるかな?」を書き始めるきっかけを作って下さった方からアドヴァイスされたこともあり、、全文検索システム"namazu"をhirax.netにインストールしてみることにした。
そこで、できた検索ページがここ(http://www.hirax.net/cgi-bin/namazu.cgi)である。こんなページである。
 |
使い方の詳細は"namazu"の検索式の詳細(http://www.namazu.org/doc/manual.html#query)を見て頂くことにして、まずは使ってみたい。「できるかな?」は科学サイトだと思われることも多い。いや、自分でもたまにそう思うこともあるのだが、全文検索をかけてみると少し違う結果が出た。
 |
なんと、13ページしかヒットしないのである。おやおや?と思い、いくつかのキーワードで検索をかけてみた。それをヒット数順に並べたのが下のリストである。
- 画像 = 74
- 色 = 51
- 可視化 = 23
- 心 = 21
- プログラム = 16
- 科学 = 13
- 恋 = 12
- 漱石 = 10
- 水着 = 5
というわけで、「あれっ、あの話はどこにあったかな?」とか「この言葉に関係した話はあったっけ?」などと考えの際はここで調べてもらいたい、と思う。
さて、こういう「検索システム」は「レーダー」と良く似ている。広大な霧の中から探しているものを見つけてくれるのである。この話の時に触れた富士山レーダーを思い出してしまう。
いや、本当のことを言えば実は話の流れは逆である。新田次郎の小説「富士山頂」、いや元気象庁観測部測器課長であった藤原寛人の富士山レーダー建設を題にとって書いた私小説と言った方が良いか、の最後を読んでいて、検索ページを作ってみることにしたのである。小説の最後で主人公(藤原寛人)は自分を自由に泳がせてくれていた直属の上司と一緒に仕事ができなくなることに呆然とする。富士山レーダー建設をさせてくれたのもその上司あってのことだと感じるわけだが、時折私が強く感じることと重なってしまって(以下、略。)