1999-07-14[n年前へ]
■夏目漱石は温泉がお好き? 
文章構造を可視化するソフトをつくる
先週は新宿で開催されていた可視化情報シンポジウム'99を見ていた。参加者の世界が狭い(ジャンルが狭いという意味ではない)し、学生の発表が多すぎるように思ったが、少なくとも本WEBのようなサイトで遊ぶには面白い話もあった。というわけで、これから何回か「可視化情報シンポジウム'99」記念の話が続くかもしれない。とりあえず、今回は「小説構造を可視化しよう」という話だ。
まずは、「可視化情報シンポジウム'99」の発表の中から一番笑わせて(笑ったのはいい意味ですよ。決して皮肉ではないですよ。しつこいようですが、ホントホント。私のツボに見事にはまったのだからしょうがない。)もらった発表のタイトルはこれである。
文学作品における文体構造の可視化 - 宮沢賢治「銀河鉄道の夜」の解析-
白百合女子大学大学院の金田氏らによる発表だ。予稿集から、その面白さを抜き出してみよう。まずは過去の研究の紹介をしている部分だ。
作品(hirax注:夏目漱石の「虞美人草」と「草枕」)の始まりから終わりまでを時系列で捉えると(hirax注:話法に関する解析をすると)、二作品はともに円環構造、つまり螺旋構造を描きながら、物語が進行していくことが、四次元空間上に表現された。
中略
これは、作品の解析結果を可視化することで、夏目漱石の思考パターンと内面の揺れが明らかにされたことを意味する。
なんて、面白いんだ。この文章自体がファンタジーである。こういうネタでタノシメル人にワタシハナリタイ。おっと、つい宮沢賢治口調になってしまった。そして、今回の発表の内容自体は、宮沢賢治の「銀河鉄道の夜」の中に出てくる単語、「ジョバンニ・カンパネルラ・二」という三つの出現分布を調べて構成を可視化してみよう、そしてその文学的観点を探ろう、という内容だ。
本サイトは実践するのを基本としている。同じように遊んでみたい。まずは、そのためのプログラムを作りたい。名づけて"WordFreq"。文章中の単語の出現分布を解析し可視化するソフトウェアである。単語検索ルーチンにはbmonkey氏の正規表現を使った文字列探索/操作コンポーネント集ver0.16を使用している。
ダウンロードはこちらだ。もちろんフリーウェアだ。しかし、バグがまだある。例えば出現平均値の計算がおかしい。時間が出来次第直すつもりだ。平均睡眠時間5時間が一月続いた頭の中は、どうやらバグにとって居心地が良いようなのだ。
wordfreq.lzh 336kB バグ有り版
バグ取りをしたものは以下だ(1999.07.22)。とりあえず、まだ上のプログラムは削除しないでおく。
失楽園殺人事件の犯人を探せ - 文章構造可視化ソフトのバグを取れ - (1999.07.22)
動作画面はこんな感じだ。「ファイル読みこみ」ボタンでテキストファイルを読みこんで、検索単語を指定して、「解析」ボタンを押すだけだ。そうすれば、赤いマークでキーワードの出現個所が示される。左の縦軸は1行(改行まで)辺りの出現個数だ。そして、横軸は文章の行番号である。すなわち、左が文章の始めであり、右が文章の終わりだ。一文ではなく一行(しかもコンピュータ内部の物理的な)単位の解析であることに注意が必要だ。あくまで、改行までが一行である。表示としての一行を意味するものではない。なお、後述の木村功氏から、「それは国語的にいうとパラグラフ(段落)である。」という助言を頂いている。であるから、国語用の解析を行うときには「行」は「段落」と読み替えて欲しい。また、改行だけの個所には注意が必要だ。それも「一行」と解釈するからである。
 |
「スムージング解析」ボタンを押せば、その出現分布をスムージングした上で、1行辺りに「キーワード」がどの程度出現しているかを解析する。
そう、この文章は長い文章の中でどのように特定の単語が出現するか解析してくれるのである。
それでは、試しに使ってみよう。まずは、結構好きな夏目漱石の小説で試してみたい。
電脳居士@木村功のホームページ
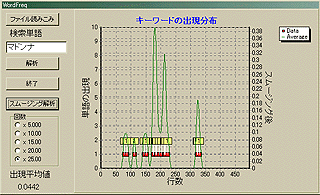
から、「ホトトギス」版 「坊っちやん」のテキストを手に入れる。そして解析をしてみよう。まずは、この画面は夏目漱石の「坊っちやん」の中で「マドンナ」という単語がどのような出現分布であるかを解析したものである。
|
文章の中ほどで「マドンナ」は登場してくるが、それほど重要なキャラクターでないことがわかる(このソフトがそう言っているんで、私が言っているのではない。だから、文句メールは送らないで欲しい)。
それでは、「湯」というキーワードで解析してみよう。「坊っちやん」と言えば道後温泉であるからだ。
 |
おやおや、「マドンナ」よりもよっぽどコンスタント(安定して、という意味で)に「湯」という単語は出現するではないか。出現平均値は「マドンナ」の方が多いが、安定度では「湯」の方が上だ。夏目漱石は「マドンナ」よりも「湯」すなわち温泉によっぽど興味があるようだ。
主人公を育てた重要人物「清」を調べてみると、こんな感じだ。
 |
小説の初めなんか出ずっぱりである。あと小説のラストにも登場している。
どうだろうか。見事に小説の可視化に成功しているだろう。結構、この解析は面白い。すごく簡単なのである。
これから新聞、WEB、小説、ありとあらゆる文章を可視化し、構造解析していくつもりだ。みなさんも、このソフトを使って面白い解析をしてみるとよいのではないだろうか? とりあえず、高校(もしかしたら大学の教養)の文学のレポートくらいは簡単に書けそうである。もし、それで単位が取れたならば、メールの一本でも送って欲しい。
というわけで、今回はソフトの紹介入門編というわけで、この辺りで終わりにしたいと思う。
1999-07-22[n年前へ]
■失楽園殺人事件の犯人を探せ
文章構造可視化ソフトのバグを取れ
今回は
夏目漱石は温泉がお好き? - 文章構造を可視化するソフトをつくる - (1999.07.14)
の続きである。やりたいことは以下の3つ
- WordFreqのバグを取る。
- 定量化に必要な数値を出す。
- とにかく遊んでみる。
WordFreq.exe 1999.07.21Make版 wordfreq.lzh 338kB
本WEBサイトのモットーは「質より量」である。...これはちょっと何だな...「下手な鉄砲も数撃ちゃ当たる」...これもちょと...「転がる石に...(もちろん日本版でなくて西洋版のだ)」といった方がニュアンスが良いかな?... 転がる石は精度を求めないのである。数をこなせば精度が悪くてもいい方角に転がっていくと思っているのだ。モンテカルロ理論である。「遊び」だし。というわけで、これはバグがあった言い訳である。
さて次は、「定量化に必要な数値を出す」である。前回の題目で使った「ホトトギス」版「坊っちやん」のダウンロード元のWEBの作成者である木村功氏より、前回の話以後にいくつかアドバイスを頂いた。それが「定量化するにはどのようにしたら良いか」ということであった。それについては、最低限の機能をつけてみた。やったのはただひとつ。出現頻度の分散を計算するようにしただけである。この数値と出現平均値を用いて、色々な文章を解析すれば、このプログラムの返す値の出現分布の分散・平均値・有意水準などを導くことができるだろう。色々な時代の、色々な作家の、色々なジャンルの文章を解析し、それらから得られた値を調べてみればもしかしたら面白いことがわかるかもしれない。
それでは、今回のプログラムを使って遊んでみよう。
今回用いるテキストは小栗虫太郎の「失楽園殺人事件」だ。
青空文庫 ( http://www.aozora.gr.jp/)
から手に入れたものだ。今回のタイトルどおり、「失楽園殺人事件」において「犯人」を探してみよう。
 |
ラストのほうに向かうに従い犯人の登場が増えて、山場を迎えているのがわかるだろう。「犯人」で検索したら次は探偵の番だ。「法水」で検索し、探偵がきちんと働いているか見てみよう。
 |
なかなか出ずっぱりで活躍している。もちろん、探偵役もラストでは活躍しているようだ。
ここまで見ていただくとわかるだろうが、画面は前回のバージョンとほとんど同じである。前回は、1物理行あたり検索単語は1個までしか見つからなかったが、今回はきちんと複数見つかっているのがわかると思う。1物理行中でもきちんと結果が出るようになったおかげで、文章中から「。」を検索すると、物理行(段落と近いもの)中に含まれる「文」の数を調べることが出来る。妙に長い文節の出現頻度などを調べることが出来るのだ。こういったものは定量化にふさわしいのではないだろうか?
 |
また、C++プログラマーのあなたは自分のプログラム中から「//」などを検索すると面白いのではないだろうか。コメントの出現頻度が手に取るようにわかるだろう。
というわけで、今回はバグ修正のご報告である。
1999-08-10[n年前へ]
■WEBページは会社の心 (色弱と色空間 その2)
WEBページのカラーを考える 3
前回、
で色弱の人の感じる色空間について少し考えてみた。また、などで、WEBページの配色やレイアウトからその会社自身について考察してみたことがある。今回は、それらを組み合わせてみたい。前回考えたやり方(ある錐体の情報を無くした際に得られる色空間をシミュレーション計算する)で色々なWEBページを解析してみるのだ。その結果として得られるものは、会社の「心」を示しているかもしれない、と思うのである。
まずは、そのためのプログラムを作成してみた。といってもごく簡単なユーティリティーである。画像ファイルを読みこみ、RGBデータの内任意の1チャンネルの情報を削除した画像を作成するのである。
実作成時間は15分程である。使いやすさはほとんど考えていないし、ボタンの押す順番によってはプログラムが簡単に落ちるというゲーム代わりにもなるものである。もし、使いたい人がいるならば、そこらへんはちゃんと直すつもりだ。それでも使うのは簡単だとは思う。今のところ、私以外に使う人がいるとも思えないので、こんなもので構わないのだ。
簡単に今回作成したプログラムTrueColorの動作画面を説明する。
 |  |
 |  |
TrueColorは画像ファイルを読みこみ、
- RGBの内の1チャンネルを全て0にする
- RGBの内の1チャンネルを他の2チャンネルの平均値にする
また、画像読みこみに関してはSusieプラグインに対応している。
使う人がいるとも思えないが、一応ここからダウンロードできる。
truecolor.lzh 360kB
それでは、各社のWEBページを調べてみる。各社のWEBを見た上で、一番識別が困難になりそうな条件で解析を行ってみた。その結果、前回調べた7社中(ただし、今回は日本国内の会社のみ)では、ある1社以外は何の問題もないように思われる。大丈夫と思われる例を示してみよう。これはアップル株式会社である。
 |  |
特に見にくい個所は見当たらない。それは他の会社についても同様であり、ある1チャンネルの情報を欠如させても特に識別しにくい個所は見当たらなかった。
さて、問題があると思われる1社はどこだろうか? そう、RICOHである。ただでさえ、見にくいデザインなのであるが赤のチャンネルの情報を削除すると文字の識別が困難になるボタンがある。このボタンのデザインは非常に見にくい。
 |  |
RICOHは内容的には非常に素晴らしいWEBなのだから、WEBの色にももう少し気を配ると良いと思う。内容が伝わらない可能性があるというのは、非常にもったいないと思う。
さて、他のWEBも調べてみよう。気を配っているはずの厚生省だ。
 |  |
1箇所ハイライト部分が識別不能(ハイライトになっていることを)であることを除けば、問題は無いようである。
さて、他のWEBを調べるなら当然本WEBについても調べなければならないだろう。
 |  |
背景に色をつけているので、若干見にくいとは思うが、うーん、落第かな... どうしたものか。
1999-08-14[n年前へ]
■年始は景気が悪いの法則
株価・為替グラフ表示ソフトを作ろう
自慢ではないが、私は経済には疎い。しかし、霞を食べて生きているわけではないので、勤務先の景気の行方は私の食生活を左右してしまう。その年の給料は年始に労使交渉の後に決まるのだが、何故か毎年その時期は勤務先の景気は悪いのである。当然、毎年不景気な労使交渉が行われることになる。
「何故か毎年その時期は勤務先の景気は悪い」と書いたが、わかっている理由もある。例えば、その前年末に売れてない製品を売れたことにして前年の売上に押しこめてしまうから、次の年始は当然製品の売れ行きが下がるわけである。従って、給料を安く抑えるためには、労使交渉を年始に行うのがいいと思われる。
そういうことはおいておいても、経済の勉強は少しはしなければならないだろう。こう思ったきっかけは、「今日の必ずトクする一言(http://www.tomoya.com/)」の
- 株価の先読みは可能か?(風水学的に店頭市場を見る編)
- (http://www.bekkoame.ne.jp/~jh6bha/higa9904.html#990427)
それでは、今回のサンプルには「カシオ計算機(株)」を使うことにしてみる。まずは、カシオ計算機の株価の最近一年間の変動を以下に示してみる。
 |
さて、これだけでは何がなんだかわからないし、カシオ計算機の特徴もわからない。
- 他の会社の平均に対してカシオ計算機の特徴はどうか?
- カシオ計算機の株価と相関があるパラメータは何か?
他の会社の平均を調べるためには、日経平均株価を見れば良いのだろう。そして、カシオ計算機のような輸出を主体とする製造業の場合は、円vsUS$為替が株価と極めて相関が高いことが多いので、日経平均株価と円vsUS$為替の変動を示してくれるサイトがあれば簡単に比較ができるだろう。例えば、そういった情報はYAHOOやASAHI..COMから得ることができる。
しかし、大雑把に探した限りでは、日経平均株価と円vsUS$為替の変動を同時に表示してくれるサイトが見当たらなかった。そこで、日経平均株価と円vsUS$為替の一年間の変動を表示するソフトウェアEconomicを作成することにした(経済の勉強から離れてしまっている気もするが...)。
プログラムの内容はごく簡単で、ASAHI.COMにアクセスして「日経平均株価」と「円vsUS$為替の変動」を示す画像を取得して、合成するだけである。今のところ、proxy対応にはしていないが、そうするのもごく簡単なので、気が向けばproxy対応にするつもりだ。
また、動作のためにはSUSIEプラグインのJPEG対応プラグインを必要とするので「Susieの部屋」から適当なプラグインをダウンロードし、Economicプログラムと同じディレクトリか、システム、もしくはSUSIEアプリケーションのあるディレクトリに入れておく必要がある(経済の勉強をするのに、何故SUSIEプラグインの話になるのだろう? というツッコミは無しだ。)。Economicプログラムは以下からダウンロードできる。
 緑 : 円vsUS$為替 紫 : 日経平均株価: |
- 他の会社の平均に対してカシオ計算機の特徴はどうか?
- カシオ計算機の株価と相関があるパラメータは何か?
それでは、このEconomicを用いて、カシオ計算機の株価の変動を見てみよう。
 | |
見比べてみると、カシオ計算機の株価は日経平均株価(左の紫の線で示してあるもの)とはあまり相関が無い。日経平均株価が右上がりで高くなっているのに対して、カシオ計算機の株価は最初に大きく低下した後に、低迷を続けている。
それに対して、円vsUS$為替の変動(左の緑の線で示してあるもの)と見比べてみると、ほぼ同じであることがわかる。輸出を行っているメーカーはどうしてもこうなってしまう。例えば、1円円高になると為替で数十億円も損失が出たりするのである。素晴らしい製品を作るかどうかよりも、円高になるか円安になるかの方が重要であったりするのだ。しかも、(私の気のせいだとは思うが)いつも年始は円高で、そのため毎年給料が不景気になるような気もするのだ。困ったものである(私が)。
さて、こういったプログラムは作るのが簡単な割に面白い(私としては)ので、色々と応用プログラムを作成して遊んでみるつもりである。そうして、いつか経済オンチを克服してみたいと思うのであった(経済の話なんかほとんど出てきてないような気もするが...)。
1999-09-08[n年前へ]
■続ACIIアートの秘密
階調変換 その1
さて、今回は
の続きである。今回はASCIIアートの階調変換に関する話である。原画像からASCII文字画像に変換するときにどう変換するか、という話の第一話である。 まずは、白から黒までの256階調の基準チャートとASCII文字によるチャートを示してみよう。
両者ともかなり縮小表示している。従って、ASCII文字チャートの方は文字がつぶれて滑らかに見えている。一見すると、ASCII文字チャートの方は白地に黒い文字を印字しているため、完全に黒いようなものは出力できない。そのため、全体的に白く見える。
これらの2つの画像のヒストグラムを示してみよう。ばらつきが多少あるが、256階調の基準チャート(上)では256階調にわたって存在している。しかし、ASCII文字チャート(下)では(ざっと見た限りでは)35階調程度しか存在していない(これは使用するフォントによって異なる)。もともと、ASCII文字は数多くあるわけではないし、平均濃度が等しい文字も存在するので、この程度になってしまうのはしょうがない。また、最も黒い領域でも、256階調の基準チャート(上)の半分程度の濃度しかない(これも使用するフォントによって異なる)。
ところどころに「使用するフォントによって異なる」という注釈を入れいるがこれが前回作成したimage2asciiの特徴である。指定のフォントを用いて画像出力を行った結果を用いてガンマテーブルを再構成するのである。逆にいえば、その指定のフォントを用いない場合には意図した画像は得られないわけである。「DeviceDepend」な技術というわけである。
 |
 |
そもそも、オリジナルの画像から、この程度の階調しかないASCII文字画像へどのように変換したら良いだろうか? 先に基準チャート(上)とASCII文字チャートの例を示したが、そもそもそのASCII文字チャートはどのようにして変換するのだろうか?
まず思いつくのはオリジナル画像の濃度に一番近い濃度の出力を行う方法である。それを濃度精度重視の変換と呼ぼう。そして、もうひとつは、オリジナル画像の中での相対濃度を基準とする変換である。すなわち、オリジナルの最大濃度をASCII文字出力による最大画像に合わせ、オリジナルの最小濃度をASCII文字出力による最小画像に合わせ、あとは単に線形に変換する方法である。こちらを(まずは単純な)階調性重視の変換と呼ぼう。その変換の構造を以下に示してみる。
 |  |
濃度精度重視の変換(左)では、ある濃度以上になると全て同じ濃度で示されてしまう。階調性重視の変換(右)ではそんなことは生じない。しかし、オリジナルの画像と変換後の画像の濃度はかなり異なってしまう。これら2つのやり方によるASCII文字チャートをそれぞれ示してみる。
濃度精度重視によるASCII文字チャートと階調性重視によるASCII文字チャート(下)のどちらが自然だろうか?濃度精度重視によるASCII文字チャートは階調の中程までは基準チャート(上)と非常に近い濃度を保っている。そのかわり、それ以降の濃度が高い部分はまったく階調性を失っている。少なくともこの基準チャート(上)のように256階調にわたり均等に濃度が存在するような画像を扱うのであれば、階調性重視によるASCII文字チャート(下)の方が自然だろう。というわけで、前回作成したimage2asciiは階調性重視による変換を用いている。
さて、今回は256階調全てにわたって滑らかな基準チャートを用いて考えてみた。しかし、実際の写真はそんなものではない。色々な濃度が均等に現れるわけではないし、そもそも狭い濃度領域しかない画像の場合もあるそういった場合には、数多くの問題が生じる。また、単に(単純な)階調性重視によるASCII文字チャート(下)が優れているわけでもなくなる。場合によって何が優れているかは異なるのだ。一般的な画像において、一体どんな問題が生じるのか、ということを次回に考えてみることにする。そして、新たに2種類の変換方法を加えてバージョンアップしたimage2asciiの登場するわけである。
今回は、その3つの変換方法の違いにより出力画像にどのような違いが生じるかを示すだけにしておく。先入観が無い状態で、優劣を判断してみると良いと思う。次の例は人物写真である。まずは、オリジナルの写真である。
 |
以下にimage2asciiを用いて変換したものを示す。
 |  |  |
これらの違いがどのようなものであるかを次回に考える。