1999-06-17[n年前へ]
■人静月同照 
ぼくらが旅に出る理由

この写真は奈良の橿原のはずれ辺りで撮影したものである。、車のボンネットの上で30秒の露出を行ったものだったと思う。まるで太陽のように輝いているのは、月だ。夜に京都を出発し、和歌山の海の近くで日の出を迎えたのだから、この写真を撮ったのは深夜だったはずだ。
和辻哲郎の随筆によれば、夏目漱石は李白の「人静月同眠」という詩を「人静月同照」だと思っていたそうだ。「人静かにして月同じく眠る」では単なる情景であるが、「人静かにして月同じく照らす」ならば思想である。和辻哲郎は、「人静かにして月同じく照らす」という言葉に漱石の人間に対する態度や、自ら到達しようと努めていた理想がこもっていたと言う。
1999-07-14[n年前へ]
■夏目漱石は温泉がお好き?
文章構造を可視化するソフトをつくる
先週は新宿で開催されていた可視化情報シンポジウム'99を見ていた。参加者の世界が狭い(ジャンルが狭いという意味ではない)し、学生の発表が多すぎるように思ったが、少なくとも本WEBのようなサイトで遊ぶには面白い話もあった。というわけで、これから何回か「可視化情報シンポジウム'99」記念の話が続くかもしれない。とりあえず、今回は「小説構造を可視化しよう」という話だ。
まずは、「可視化情報シンポジウム'99」の発表の中から一番笑わせて(笑ったのはいい意味ですよ。決して皮肉ではないですよ。しつこいようですが、ホントホント。私のツボに見事にはまったのだからしょうがない。)もらった発表のタイトルはこれである。
文学作品における文体構造の可視化 - 宮沢賢治「銀河鉄道の夜」の解析-
白百合女子大学大学院の金田氏らによる発表だ。予稿集から、その面白さを抜き出してみよう。まずは過去の研究の紹介をしている部分だ。
作品(hirax注:夏目漱石の「虞美人草」と「草枕」)の始まりから終わりまでを時系列で捉えると(hirax注:話法に関する解析をすると)、二作品はともに円環構造、つまり螺旋構造を描きながら、物語が進行していくことが、四次元空間上に表現された。
中略
これは、作品の解析結果を可視化することで、夏目漱石の思考パターンと内面の揺れが明らかにされたことを意味する。
なんて、面白いんだ。この文章自体がファンタジーである。こういうネタでタノシメル人にワタシハナリタイ。おっと、つい宮沢賢治口調になってしまった。そして、今回の発表の内容自体は、宮沢賢治の「銀河鉄道の夜」の中に出てくる単語、「ジョバンニ・カンパネルラ・二」という三つの出現分布を調べて構成を可視化してみよう、そしてその文学的観点を探ろう、という内容だ。
本サイトは実践するのを基本としている。同じように遊んでみたい。まずは、そのためのプログラムを作りたい。名づけて"WordFreq"。文章中の単語の出現分布を解析し可視化するソフトウェアである。単語検索ルーチンにはbmonkey氏の正規表現を使った文字列探索/操作コンポーネント集ver0.16を使用している。
ダウンロードはこちらだ。もちろんフリーウェアだ。しかし、バグがまだある。例えば出現平均値の計算がおかしい。時間が出来次第直すつもりだ。平均睡眠時間5時間が一月続いた頭の中は、どうやらバグにとって居心地が良いようなのだ。
wordfreq.lzh 336kB バグ有り版
バグ取りをしたものは以下だ(1999.07.22)。とりあえず、まだ上のプログラムは削除しないでおく。
失楽園殺人事件の犯人を探せ - 文章構造可視化ソフトのバグを取れ - (1999.07.22)
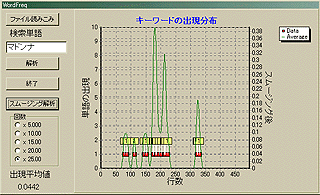
動作画面はこんな感じだ。「ファイル読みこみ」ボタンでテキストファイルを読みこんで、検索単語を指定して、「解析」ボタンを押すだけだ。そうすれば、赤いマークでキーワードの出現個所が示される。左の縦軸は1行(改行まで)辺りの出現個数だ。そして、横軸は文章の行番号である。すなわち、左が文章の始めであり、右が文章の終わりだ。一文ではなく一行(しかもコンピュータ内部の物理的な)単位の解析であることに注意が必要だ。あくまで、改行までが一行である。表示としての一行を意味するものではない。なお、後述の木村功氏から、「それは国語的にいうとパラグラフ(段落)である。」という助言を頂いている。であるから、国語用の解析を行うときには「行」は「段落」と読み替えて欲しい。また、改行だけの個所には注意が必要だ。それも「一行」と解釈するからである。
 |
「スムージング解析」ボタンを押せば、その出現分布をスムージングした上で、1行辺りに「キーワード」がどの程度出現しているかを解析する。
そう、この文章は長い文章の中でどのように特定の単語が出現するか解析してくれるのである。
それでは、試しに使ってみよう。まずは、結構好きな夏目漱石の小説で試してみたい。
電脳居士@木村功のホームページ
から、「ホトトギス」版 「坊っちやん」のテキストを手に入れる。そして解析をしてみよう。まずは、この画面は夏目漱石の「坊っちやん」の中で「マドンナ」という単語がどのような出現分布であるかを解析したものである。
|
文章の中ほどで「マドンナ」は登場してくるが、それほど重要なキャラクターでないことがわかる(このソフトがそう言っているんで、私が言っているのではない。だから、文句メールは送らないで欲しい)。
それでは、「湯」というキーワードで解析してみよう。「坊っちやん」と言えば道後温泉であるからだ。
 |
おやおや、「マドンナ」よりもよっぽどコンスタント(安定して、という意味で)に「湯」という単語は出現するではないか。出現平均値は「マドンナ」の方が多いが、安定度では「湯」の方が上だ。夏目漱石は「マドンナ」よりも「湯」すなわち温泉によっぽど興味があるようだ。
主人公を育てた重要人物「清」を調べてみると、こんな感じだ。
 |
小説の初めなんか出ずっぱりである。あと小説のラストにも登場している。
どうだろうか。見事に小説の可視化に成功しているだろう。結構、この解析は面白い。すごく簡単なのである。
これから新聞、WEB、小説、ありとあらゆる文章を可視化し、構造解析していくつもりだ。みなさんも、このソフトを使って面白い解析をしてみるとよいのではないだろうか? とりあえず、高校(もしかしたら大学の教養)の文学のレポートくらいは簡単に書けそうである。もし、それで単位が取れたならば、メールの一本でも送って欲しい。
というわけで、今回はソフトの紹介入門編というわけで、この辺りで終わりにしたいと思う。
1999-07-18[n年前へ]
■hixの地図
好きな話は何処にある?
最近、本WEBのTopページが非常に読みにくくなっている。話題が多すぎるのだ。これでは、このWEBを見に来てくれた人がいたとしても、迷ってしまうだろう。きっと、好みに合うページを見つける前に他のWEBサイトにとんでしまうに違いない。自分の好きにやっているサイトとは言え、それは少し寂しい。そこで、自らhiraxサイトの内容について解説してみることにした。といっても、単に解説するのではつまらないので、多少の考察を含めながら、である。
他の人のWEBなどを眺めながら、自分のWEBの特徴を振り返ってみると、下のような図を持ち出すのが一番良いような気がする。これは横軸を「技術度」、縦軸を「感性度(完成度にあらず)」にしたものである。ジャンル1,2,3,4は大雑把に傾向で分類しようとしたものである。
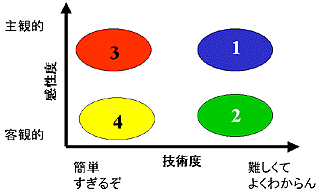 |
他の技術系サイトを見た後に本WEBを見ると、どうも本WEBは技術的でない話が多い。主観的な部分がかなり含まれているのだ。他の技術サイトでももちろん主観的な部分はある。しかも、(私にはまだまだ出来ないのだが)説得力があるのだ。すなわち、ある程度の客観性が感じられる。しかし、私のサイトの中にある主観的な話は他の人に説得力があるとは思えないのである。妙な感覚的な話と技術的な話のカクテルみたいなのである。そこで、上のようなグラフが登場するわけである。
科学という立場から考えれば、客観的であり技術的にも高度な「ジャンル-2」が望ましいだろう。しかし、本WEBには技術的には高度でないし、客観性もない、という「ジャンル-3」も多い。例えば、
iMacはドラえもんの夢を見るか? -さようなら、ドラえもん - (1999.02.03)
などがそうだ。そして、その極限として「Scraps」がある。こういった状況が良いのか悪いのかよくわからないが、とりあず、それもまた個性ということにしておこう。
「ジャンル-4」の代表的な話としては
鴨川カップルの謎 -そうだ、京都、行こう-(1998.11.29)
というところか。「ジャンル-1」としては
コピー機と微分演算子-電子写真プロセスを分数階微分で解いてみよう-(1999.06.10)
というところで、「ジャンル-2」は
夏目漱石は温泉がお好き? -文章構造を可視化するソフトをつくる - (1999.07.14)
という感じだろう。まずは、自分の好みとあった所から眺めてみて頂きたい。また、裏で繋がっている話も多いのでそういう伏線を探してみるのも面白いのではないだろうか。
なお、私の書く文章ははどうも「本当に言いたいことを行間に隠してしまう」ようなので(表現力がないとも言う)、行間に隠れている(作者も気づいていない)応用など読みとって頂けたら幸いである。それを私に教えていただければ、なお良い。
1999-07-22[n年前へ]
■失楽園殺人事件の犯人を探せ
文章構造可視化ソフトのバグを取れ
今回は
夏目漱石は温泉がお好き? - 文章構造を可視化するソフトをつくる - (1999.07.14)
の続きである。やりたいことは以下の3つ
- WordFreqのバグを取る。
- 定量化に必要な数値を出す。
- とにかく遊んでみる。
WordFreq.exe 1999.07.21Make版 wordfreq.lzh 338kB
本WEBサイトのモットーは「質より量」である。...これはちょっと何だな...「下手な鉄砲も数撃ちゃ当たる」...これもちょと...「転がる石に...(もちろん日本版でなくて西洋版のだ)」といった方がニュアンスが良いかな?... 転がる石は精度を求めないのである。数をこなせば精度が悪くてもいい方角に転がっていくと思っているのだ。モンテカルロ理論である。「遊び」だし。というわけで、これはバグがあった言い訳である。
さて次は、「定量化に必要な数値を出す」である。前回の題目で使った「ホトトギス」版「坊っちやん」のダウンロード元のWEBの作成者である木村功氏より、前回の話以後にいくつかアドバイスを頂いた。それが「定量化するにはどのようにしたら良いか」ということであった。それについては、最低限の機能をつけてみた。やったのはただひとつ。出現頻度の分散を計算するようにしただけである。この数値と出現平均値を用いて、色々な文章を解析すれば、このプログラムの返す値の出現分布の分散・平均値・有意水準などを導くことができるだろう。色々な時代の、色々な作家の、色々なジャンルの文章を解析し、それらから得られた値を調べてみればもしかしたら面白いことがわかるかもしれない。
それでは、今回のプログラムを使って遊んでみよう。
今回用いるテキストは小栗虫太郎の「失楽園殺人事件」だ。
青空文庫 ( http://www.aozora.gr.jp/)
から手に入れたものだ。今回のタイトルどおり、「失楽園殺人事件」において「犯人」を探してみよう。
 |
ラストのほうに向かうに従い犯人の登場が増えて、山場を迎えているのがわかるだろう。「犯人」で検索したら次は探偵の番だ。「法水」で検索し、探偵がきちんと働いているか見てみよう。
 |
なかなか出ずっぱりで活躍している。もちろん、探偵役もラストでは活躍しているようだ。
ここまで見ていただくとわかるだろうが、画面は前回のバージョンとほとんど同じである。前回は、1物理行あたり検索単語は1個までしか見つからなかったが、今回はきちんと複数見つかっているのがわかると思う。1物理行中でもきちんと結果が出るようになったおかげで、文章中から「。」を検索すると、物理行(段落と近いもの)中に含まれる「文」の数を調べることが出来る。妙に長い文節の出現頻度などを調べることが出来るのだ。こういったものは定量化にふさわしいのではないだろうか?
 |
また、C++プログラマーのあなたは自分のプログラム中から「//」などを検索すると面白いのではないだろうか。コメントの出現頻度が手に取るようにわかるだろう。
というわけで、今回はバグ修正のご報告である。
1999-09-01[n年前へ]
■画像に関する場の理論
ポイントは画像形成の物理性だ!?
今回は、
夏目漱石は温泉がお好き? - 文章構造を可視化するソフトをつくる- (1999.07.14)
の回と同じく、「可視化情報シンポジウム'99」から話は始まる。まずは、「可視化情報シンポジウム'99」の中の
ウェーブレット変換法と微積分方程式によるカラー画像の圧縮および再現性について
という予稿の冒頭部分を抜き出してみる。「コンピュータグラフィックスを構成する画素データをスカラーポテンシャルあるいはベクトルポテンシャルの1成分とみなし、ベクトルの概念を導入することで古典物理学の集大成である場の理論が適用可能であることを提案している」というフレーズがある。
着目点は面白いし、この文章自体もファンタジーで私のツボに近い。しかしながら、肝心の内容が私の趣向とは少し違った。何しろ「以上により本研究では、古典物理学の場の理論で用いられるラプラシアン演算を用いることで、画像のエッジ抽出が行えることがわかった。」というようなフレーズが出てくるのである。うーん。
私と同様の印象を受けた人も他にいたようで(当然いると思うが)、「エッジ強調・抽出のために画像のラプラシアンをとるのはごく普通に行われていることだと思うのですが、何か新しい事項などあるのでしょうか?」という質問をしていた人もいた。
また、話の後半では、画像圧縮のために、ラプラシアンをかけたデータに積分方程式や有限要素法などを用いて解くことにより、画像圧縮復元をしようと試みていたが、これも精度、圧縮率、計算コストを考えるといま一つであると思う(私としては)。
画像とポテンシャルを結びつけて考えることは多い。例えば、「できるかな?」の中からでも抜き出してみると、
- 分数階微分に基づく画像特性を考えてみたい- 同じ年齢でも大違い - (1999.02.28)
- ゼロックス写真とセンチメンタルな写真 - コピー機による画像表現について考える- (99.06.06)
- コピー機と微分演算子-電子写真プロセスを分数階微分で解いてみよう-(1999.06.10)
現実問題として、実世界において画像形成をを行うには物理学的な現象を介して行う以外にはありえない。「いや、そんなことはない。心理学的に、誰かがオレの脳みそに画像を飛ばしてくる。」というブラックなことを仰る方もいるだろうが、それはちょっと別にしておきたい。
「できるかな?」に登場している画像を形成装置には、
コピー機と微分演算子-電子写真プロセスを分数階微分で解いてみよう-(1999.06.10)
ゼロックス写真とセンチメンタルな写真- コピー機による画像表現について考える - (99.06.06)
で扱ったコピー機などの電子写真装置や、
宇宙人はどこにいる? - 画像復元を勉強してみたいその1-(1999.01.10)
で扱ったカメラ。望遠鏡などの光学系や、
ヒトは電磁波の振動方向を見ることができるか?- はい。ハイディンガーのブラシをご覧下さい - (1999.02.26)
で扱った液晶ディスプレイなどがある。そのいずれもが、純物理学的な現象を用いた画像形成の装置である。
例えば、プラズマディスプレイなどはプラズマアドレス部分に放電を生じさせて、電荷を液晶背面に付着させて、その電荷により発生する電界によって液晶の配向方向を変化させて、透過率を変化させることにより、画像を形成するのである。
 |
また、逆問題のようであるが電界・電荷分布測定などを目的として液晶のボッケルス効果を用いることも多い。液晶を用いて得られる画像から、電界分布や電荷分布を計測するわけである。これなども画像と場の理論が直に結びついている一例である。
参考に、SHARPのプラズマアドレスディスプレイを示しておく。
 |
また、電子写真装置などは感光体表面に電荷分布を形成し、その電位像をトナーという電荷粒子で可視化するのであるから、電磁場を用いて画像形成をしているわけである。だから、場の理論を持ちこむのは至極当然であり、有用性も非常に高いだろう。そういった視点で考察してみたのが、
である。 同様に、画像圧縮に関しても、画像形成の物理性に着目することで実現できる場合も多いと思うのであるが、それは次回にしておく。