1999-02-28[n年前へ]
■分数階微分に基づく画像特性を考えてみたい 
同じ年齢でも大違い
前回、分数階微分の謎 - 線形代数、分数階微分、シュレディンガー方程式の三題話- で分数階微分について調べた。例えば、0.7階微分といった、整数階でない微分である。今回はそれを使った応用を考えてみたい。
人間の視覚というものは明るいものは強く感じることができる。これは当たり前である。そして、それだけでなく、強さが変化している所にも(興味を)強く感じ取るようになっている。岡本安春氏の「Delphiでエンジョイプログラミング」によれば、そのような考えはLaming(1986)がdifferential coupling(差動結合)として発表しているらしい。
ということは、人間が画像を感じる特性というものは、画像強度と画像強度変化(画像強度の一階微分)の中間的なものであると言うことができるかもしれない。とすれば、分数階微分を導入すれば面白い表現ができるかもしれない。
今回は、そういう考えのもとに分数階微分を用いて人間の画像特性について考えてみたい。
まずは、元画像を示す。元画像はガウス分布に基づいて作成されたものである。
 |  |
まずは、左の元画像を見て欲しい。どこに強い感じを受けるだろうか?白い部分はもちろんであるが、白と黒の境界部にも強い感じを受けるだろう。ギザギザになっているのはデータが少ないからなので、無視して欲しい。というわけで、人間の視覚画像特性は
- 画像強度
- 画像強度変化(画像強度の一階微分)
元画像 | |
 1/2階微分画像 |  |
 15/20階微分画像 |  |
 1階微分画像 | 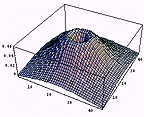 |
白地に黒画像バージョンも示しておく。紙の上の画像に慣れた人にはこちらの方が良いだろう。
 元画像 |
 1/2階微分画像 |
 15/20階微分画像 |
 1階微分画像 |
なお、今回の画像の作成は次のような手順で行っている。
- 1次元のガウス分布を作成する。
- 微分値が正であるような半分の領域を線対称に回転させ、2次元画像を作成する。
今回は
- 画像強度
- 画像強度変化(画像強度の一階微分)
- 電位
- 電界(電位の微分、といっても本来は電位が電界の積分か)
- 人口密度
- 人口密度変化(人口密度の微分)
さて、分数階微分を調べる中で、バナッハ空間についても調べた。調べ始めた時には、聞き覚えもなかったが、調べてみるとヒルベルト空間の導入で登場していた。きれいさっぱり忘れていたようである。
京大数学教室 徳永健一氏のWEB (http://www.kusm.kyoto-u.ac.jp/~kenichi/)
から辿れる「「年齢の本」数学者版」によれば
バナッハがバナッハ空間を提唱したのは30歳の時であるらしい。(http://www.kusm.kyoto-u.ac.jp/~kenichi/age/30.html)
うーん...
1999-03-28[n年前へ]
■ハードディスクのエントロピーは増大するか?
デフラグと突然変異の共通点
fjでKByteの定義(よく言われる話だが)が話題になっていた。「なんで1024Byteが1KByteなんですか」というものである。そのスレッドの中で、
- 整数値だけでなく、分数値のbitもある
- 1bitのエントロピーも定義できるはずで、それならハードディスクは結構エントロピーを持つかも
初めに、「整数値だけでなく、分数値のbitもある」という方は簡単である。{0,1}どちらかであるような状態は1bitあれば表現できる。{0,1,2,3}の4通りある状態なら2bitあれば表現できる。{0,1,2,3,4,5,6,7}までなら3bitあればいい。それでは、サイコロのような状態が6通りあるものはどうだろうか? これまでの延長で行くならば、2bitと3bitの中間であることはわかる。2進数の仕組みなどを考えれば、答えをNbitとするならば、2^N=6であるから、log_2 ^6で2.58496bitとなる。2.58496bitあれば表現できるわけだ。
後の「1bitのエントロピーも定義できるはず」というのはちょっと違うような気もする。そもそもエントロピーの単位にもbitは使われるからだ。しかし、ハードディスクのエントロピーというのはとても面白い考えだと思う。
そこで、ハードディスクのエントロピーを調べてみたい。
次のような状態を考えていくことにする。
- きれいにハードディスクがフォーマットされている状態。
- ハードディスクの内容が画像、テキストファイル、圧縮ファイル、未使用部分に別れる。
- その上、フラグメントが生じる。
画像ファイル、テキストファイル、圧縮ファイル、未使用部分を1Byteグレイ画像データとして可視化してみる。
 |  |  |  |
ところで、このような可視化をすると、ファイルの種類による差がよくわかる。てんでばらばらに見えるものは冗長性が低いのである。逆に同じ色が続くようなものは冗長性が高い。こうしてみると、LZH圧縮ファイルの冗長性が極めて低いことがよくわかる。逆に日本語テキストデータは冗長性が高い。もちろん、単純な画像はそれ以上である。
それでは、これらのようなファイルがハードディスクに格納された状態を考える。
- きれいにハードディスクがフォーマットされている状態。
- ハードディスクの内容が画像、テキストファイル、圧縮ファイル、未使用部分に別れる。
- その上、フラグメントが生じる。
 |  |  |
横方向の1ライン分を一区画と考える。ハードディスクならセクタといったところか。その区画内でのヒストグラムを計算すると以下のようになる。この図では横方向が0から255までの存在量を示し、縦方向は区画を示している。
 |  |  |
LZH圧縮ファイル部分では0から255までのデータがかなり均等に出現しているのがわかる。日本語テキストデータなどでは出現頻度の高いものが存在しているのがわかる。
それでは、無記憶情報源(Zero-memory Source)モデルに基づいて、各区画毎のエントロピーを計算してみる。
 |  |  |
これを見ると次のようなことがわかる。
- 未使用ハードディスクは全区画にわたりエントロピーは0である
- 3種類のファイルが格納された状態では、それぞれエントロピーの状態が違う。
- 画像ファイルでは複雑な画像部分がエントロピーが高い
- 日本語テキストファイル部分は結構エントロピーが高い。
- LZH圧縮ファイル部分はエントロピーが高い。
- フラグメントが生じると、トータルではエントロピーが高くなる。
- しかし、平均的に先のLZH圧縮ファイル部分の状態よりは低い。
0 | 691.28 | 982.139 |
というわけで、今回の結論
「ハードディスクのエントロピーは増大する。」
が導き出される。もし、ハードディスクのデフラグメントを行えば、エントロピーは減少することになる。
こういった情報理論を作り上げた人と言えば、Shannonなのであろうが、Shannonの本が見つからなかったので、今回はWienerの"CYBERNETICS"を下に示す。もう40年位の昔の本ということになる。その流れを汲む「物理の散歩道」などもその時代の本だ。
 |
生物とエントロピーの関係に初めて言及したのはシュレディンガーだと言う。ハードディスクと同じく、企業や社会の中でもエントロピーは増大するしていくだろう。突然変異(あるいは、ハードディスクで言えばデフラグメント)のような現象が起きて、エントロピーが減少しない限り、熱的死(いや企業や会社であれば画一化、平凡化、そして、衰退だろうか)を迎えてしまうのだろう。
1999-06-28[n年前へ]
■風呂場の水滴を考える。
オールヌードの研究員
風呂場の天井から浴槽めがけて、水滴がしたたって音がしているのはよくある風景である。ピーンという(もちろん人によっても印象は違うのだろうが)気持ちのいい音がしている。似たようなものとしては、水琴窟などもある。この音がなぜ鳴るかは、ロゲルギストの「物理の散歩道」に詳しい考察がある。それによれば、水滴が一粒落ちたように見えても、実は何粒かに別れており、ちょうどカルガモの親子のようになっているという。つまり、大きな親の水滴の一粒の後を、何粒かの小さな子どもの水滴が追いかけているという具合である。まず、水滴の親が水面に空洞をつくり、その中に子どもの水滴が飛び込むことにより音が出るという。結局、水滴の音を作っているのは、その子どもの水滴の方だという。「物理の散歩道」の中では、針をつたって水滴を落とせば、子どもの水滴ができないという。
風呂に入って、濡らした手から水滴を落としてみる。指の爪の先から水滴を落とすと音はほとんどしないが、指の「はら」から落とすと派手に音がする。ぜひ、自分でも確かめていただきたい。
爪先は比較的尖っているので、落ちる水滴は一粒だが、比較的平らな指の「はら」からの場合には、カルガモ親子のような水滴が落ちているせいだろう。
なぜ、このような違いが生じるかを推測してみたい。まずは、下の絵を見て欲しい。
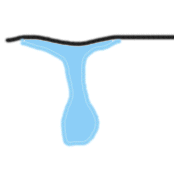 |  |
上の上手な絵が言いたいのは、次のような推測である。
- 平らな表面から水滴が落ちる際には、長く伸びた水のブリッジが出来ていて、1つぶ目の水滴が落ちた後も、このブリッジ部分が「カルガモの子ども」のように小さな水滴となって後を追いかけていくのではないか。
- それに対して、尖った表面から水滴が落ちる際には、先のブリッジ部分のほとんどは水でないため、後続の水滴は発生しない。
計算モデルとしてどのようなものを使うかであるが、私の知っている範囲では大きく分けて2種類のやり方がある。
- 流体をモデル計算する。すなわち、Navier-Stokesの方程式を解く。
- 流体を粒子のようなものの連続体として解く(ex.格子ボルツマン法)
電気通信大学情報工学科情報数理工学講座渡辺研究室( http://assam.im.uec.ac.jp/fluid.html )
 |
また、水滴が水面に衝突する状態の計算は、電気通信大学情報工学科情報数理工学講座渡辺研究室にもあるし、他にもNaSt2DというFreeの2次元Navier-Stokes方程式のソルバーを用いて行われた計算結果が
http://www5.informatik.tu-muenchen.de/forschung/visualisierung/praktikum.html
にある。
 |
Michael Griebel氏らによるNast2Dのコードは公開されているので、その中身をいじりながら、計算を行う予定である。
とりあえず、今回はバックグラウンドを紹介する所までで、次回(といってもすぐではないだろう)に計算の本番に入りたい。
手のひらの実験から考えると、風呂場で水滴の音が聞こえるのは天井が平らなせいだということになる。ならば、鍾乳石のようなつらら形状の天井の風呂場では音がしないのだろうか?しかし、水滴は空気中で落下していく最中には空気の抵抗をうける。そのため、大きな水滴は落ちる最中に分裂し、複数の水滴になってしまう。
となると、
- 落ちる水滴の最初の大きさは、どう決まっているのか。
- 水滴は落下するスピード、水滴の大きさがどの程度になると分裂するのか?
ところで、インクジェット方式のカラープリンターも液滴で画像を描くのだから、液滴の様子は重要な筈である。液滴が飛び散ってしまっては困るし、位置がずれても困る。各社ともカルガモの子ども水滴をなくすために色々工夫をこらしている筈だ。
実は風呂場の水滴問題は重要で、奥が深いのだ。オールヌードで私は考えるのであった。
1999-07-14[n年前へ]
■夏目漱石は温泉がお好き?
文章構造を可視化するソフトをつくる
先週は新宿で開催されていた可視化情報シンポジウム'99を見ていた。参加者の世界が狭い(ジャンルが狭いという意味ではない)し、学生の発表が多すぎるように思ったが、少なくとも本WEBのようなサイトで遊ぶには面白い話もあった。というわけで、これから何回か「可視化情報シンポジウム'99」記念の話が続くかもしれない。とりあえず、今回は「小説構造を可視化しよう」という話だ。
まずは、「可視化情報シンポジウム'99」の発表の中から一番笑わせて(笑ったのはいい意味ですよ。決して皮肉ではないですよ。しつこいようですが、ホントホント。私のツボに見事にはまったのだからしょうがない。)もらった発表のタイトルはこれである。
文学作品における文体構造の可視化 - 宮沢賢治「銀河鉄道の夜」の解析-
白百合女子大学大学院の金田氏らによる発表だ。予稿集から、その面白さを抜き出してみよう。まずは過去の研究の紹介をしている部分だ。
作品(hirax注:夏目漱石の「虞美人草」と「草枕」)の始まりから終わりまでを時系列で捉えると(hirax注:話法に関する解析をすると)、二作品はともに円環構造、つまり螺旋構造を描きながら、物語が進行していくことが、四次元空間上に表現された。
中略
これは、作品の解析結果を可視化することで、夏目漱石の思考パターンと内面の揺れが明らかにされたことを意味する。
なんて、面白いんだ。この文章自体がファンタジーである。こういうネタでタノシメル人にワタシハナリタイ。おっと、つい宮沢賢治口調になってしまった。そして、今回の発表の内容自体は、宮沢賢治の「銀河鉄道の夜」の中に出てくる単語、「ジョバンニ・カンパネルラ・二」という三つの出現分布を調べて構成を可視化してみよう、そしてその文学的観点を探ろう、という内容だ。
本サイトは実践するのを基本としている。同じように遊んでみたい。まずは、そのためのプログラムを作りたい。名づけて"WordFreq"。文章中の単語の出現分布を解析し可視化するソフトウェアである。単語検索ルーチンにはbmonkey氏の正規表現を使った文字列探索/操作コンポーネント集ver0.16を使用している。
ダウンロードはこちらだ。もちろんフリーウェアだ。しかし、バグがまだある。例えば出現平均値の計算がおかしい。時間が出来次第直すつもりだ。平均睡眠時間5時間が一月続いた頭の中は、どうやらバグにとって居心地が良いようなのだ。
wordfreq.lzh 336kB バグ有り版
バグ取りをしたものは以下だ(1999.07.22)。とりあえず、まだ上のプログラムは削除しないでおく。
失楽園殺人事件の犯人を探せ - 文章構造可視化ソフトのバグを取れ - (1999.07.22)
動作画面はこんな感じだ。「ファイル読みこみ」ボタンでテキストファイルを読みこんで、検索単語を指定して、「解析」ボタンを押すだけだ。そうすれば、赤いマークでキーワードの出現個所が示される。左の縦軸は1行(改行まで)辺りの出現個数だ。そして、横軸は文章の行番号である。すなわち、左が文章の始めであり、右が文章の終わりだ。一文ではなく一行(しかもコンピュータ内部の物理的な)単位の解析であることに注意が必要だ。あくまで、改行までが一行である。表示としての一行を意味するものではない。なお、後述の木村功氏から、「それは国語的にいうとパラグラフ(段落)である。」という助言を頂いている。であるから、国語用の解析を行うときには「行」は「段落」と読み替えて欲しい。また、改行だけの個所には注意が必要だ。それも「一行」と解釈するからである。
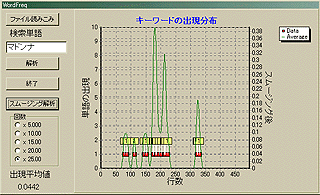 |
「スムージング解析」ボタンを押せば、その出現分布をスムージングした上で、1行辺りに「キーワード」がどの程度出現しているかを解析する。
そう、この文章は長い文章の中でどのように特定の単語が出現するか解析してくれるのである。
それでは、試しに使ってみよう。まずは、結構好きな夏目漱石の小説で試してみたい。
電脳居士@木村功のホームページ
から、「ホトトギス」版 「坊っちやん」のテキストを手に入れる。そして解析をしてみよう。まずは、この画面は夏目漱石の「坊っちやん」の中で「マドンナ」という単語がどのような出現分布であるかを解析したものである。
|
文章の中ほどで「マドンナ」は登場してくるが、それほど重要なキャラクターでないことがわかる(このソフトがそう言っているんで、私が言っているのではない。だから、文句メールは送らないで欲しい)。
それでは、「湯」というキーワードで解析してみよう。「坊っちやん」と言えば道後温泉であるからだ。
 |
おやおや、「マドンナ」よりもよっぽどコンスタント(安定して、という意味で)に「湯」という単語は出現するではないか。出現平均値は「マドンナ」の方が多いが、安定度では「湯」の方が上だ。夏目漱石は「マドンナ」よりも「湯」すなわち温泉によっぽど興味があるようだ。
主人公を育てた重要人物「清」を調べてみると、こんな感じだ。
 |
小説の初めなんか出ずっぱりである。あと小説のラストにも登場している。
どうだろうか。見事に小説の可視化に成功しているだろう。結構、この解析は面白い。すごく簡単なのである。
これから新聞、WEB、小説、ありとあらゆる文章を可視化し、構造解析していくつもりだ。みなさんも、このソフトを使って面白い解析をしてみるとよいのではないだろうか? とりあえず、高校(もしかしたら大学の教養)の文学のレポートくらいは簡単に書けそうである。もし、それで単位が取れたならば、メールの一本でも送って欲しい。
というわけで、今回はソフトの紹介入門編というわけで、この辺りで終わりにしたいと思う。
1999-07-22[n年前へ]
■失楽園殺人事件の犯人を探せ
文章構造可視化ソフトのバグを取れ
今回は
夏目漱石は温泉がお好き? - 文章構造を可視化するソフトをつくる - (1999.07.14)
の続きである。やりたいことは以下の3つ
- WordFreqのバグを取る。
- 定量化に必要な数値を出す。
- とにかく遊んでみる。
WordFreq.exe 1999.07.21Make版 wordfreq.lzh 338kB
本WEBサイトのモットーは「質より量」である。...これはちょっと何だな...「下手な鉄砲も数撃ちゃ当たる」...これもちょと...「転がる石に...(もちろん日本版でなくて西洋版のだ)」といった方がニュアンスが良いかな?... 転がる石は精度を求めないのである。数をこなせば精度が悪くてもいい方角に転がっていくと思っているのだ。モンテカルロ理論である。「遊び」だし。というわけで、これはバグがあった言い訳である。
さて次は、「定量化に必要な数値を出す」である。前回の題目で使った「ホトトギス」版「坊っちやん」のダウンロード元のWEBの作成者である木村功氏より、前回の話以後にいくつかアドバイスを頂いた。それが「定量化するにはどのようにしたら良いか」ということであった。それについては、最低限の機能をつけてみた。やったのはただひとつ。出現頻度の分散を計算するようにしただけである。この数値と出現平均値を用いて、色々な文章を解析すれば、このプログラムの返す値の出現分布の分散・平均値・有意水準などを導くことができるだろう。色々な時代の、色々な作家の、色々なジャンルの文章を解析し、それらから得られた値を調べてみればもしかしたら面白いことがわかるかもしれない。
それでは、今回のプログラムを使って遊んでみよう。
今回用いるテキストは小栗虫太郎の「失楽園殺人事件」だ。
青空文庫 ( http://www.aozora.gr.jp/)
から手に入れたものだ。今回のタイトルどおり、「失楽園殺人事件」において「犯人」を探してみよう。
 |
ラストのほうに向かうに従い犯人の登場が増えて、山場を迎えているのがわかるだろう。「犯人」で検索したら次は探偵の番だ。「法水」で検索し、探偵がきちんと働いているか見てみよう。
 |
なかなか出ずっぱりで活躍している。もちろん、探偵役もラストでは活躍しているようだ。
ここまで見ていただくとわかるだろうが、画面は前回のバージョンとほとんど同じである。前回は、1物理行あたり検索単語は1個までしか見つからなかったが、今回はきちんと複数見つかっているのがわかると思う。1物理行中でもきちんと結果が出るようになったおかげで、文章中から「。」を検索すると、物理行(段落と近いもの)中に含まれる「文」の数を調べることが出来る。妙に長い文節の出現頻度などを調べることが出来るのだ。こういったものは定量化にふさわしいのではないだろうか?
 |
また、C++プログラマーのあなたは自分のプログラム中から「//」などを検索すると面白いのではないだろうか。コメントの出現頻度が手に取るようにわかるだろう。
というわけで、今回はバグ修正のご報告である。