2000-04-01[n年前へ]
■恋の力学 恋の相関分析編 
「明暗」の登場人物達の行方
「恋の力学」シリーズである。前書き編が登場したきりで、なかなか本編に入らない「恋の固体物理学」シリーズではない。今回は、
の続き、ということになる。以前、
の中で書いたように、恋の力学シリーズは夏目漱石の影響を多大に受けている。そして、同様に夏目漱石の影響を受けているシリーズがある。それは「文章構造可視化シリーズ」である。何しろ、「文章構造可視化シリーズ」は夏目漱石をきっかけとして、始まっているのである。また、シリーズの中の話を見ればわかるように、
- 夏目漱石は温泉がお好き?- 文章構造を可視化するソフトをつくる - (1999.07.14)
- 失楽園殺人事件の犯人を探せ- 文章構造可視化ソフトのバグを取れ - (1999.07.22)
- 「こころ」の中の「どうして?」 -漱石の中の謎とその終焉 - (1999.09.10)
- 「星の王子さま」の秘密- 水が意味するもの - (1999.11.15)
そのための準備として、まずは「文章構造可視化シリーズ」で作成した"wordfreq"をバージョンアップしてみた。その動作画面を以下に示す。
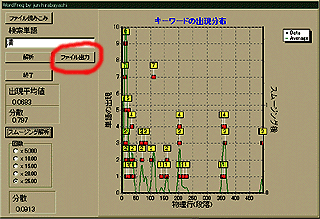 |
赤丸で示したボタンに「ファイル出力」と書いてあるのがわかると思う。つまり、文章中に「任意の単語」が出現した出現頻度を解析した結果をファイル出力する機能を持たせたのだ。1段落中に「任意の単語」が出現した数をテキスト形式で出力するようにしてある。このファイル出力結果を他のソフトに読み込めば、色々な解析ができるわけだ。いつものように、このソフトはここ
においておく。言うまでもないが、アルファ版の中のアルファ版だ。さて、今回用いるテキストは
でも登場した「明暗」である。そこで、「青空文庫」から「明暗」の電子テキストをダウンロードした。そして、バージョンアップした"wordfreq"で- 津田
- お延
- 清子
- 吉川
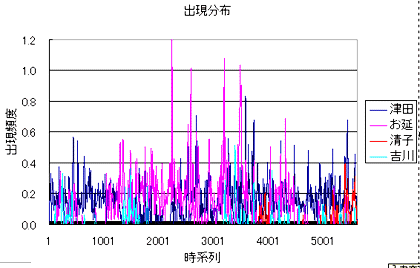 |
しかし、これだけでは、よくわからない。せいぜい「清子」が小説の後半(といっても、未完であるが)に登場しているなぁ、という位だろう。しかし、さらに解析を加えてみると、もう少し面白いことがわかる。
今回は、これらの登場人物間のお互いの関わりを調べたいのである。であるならば、これらの「登場人物」の出現分布の間の相関を調べてみると面白いだろう。互いの関係を示す「相関」を調べてみるのである。異なる「登場人物」が同じような出現をしているならば、それは無関係ではない。きっと、その登場人物の間には何らかの関係があるに違いないのだ。
そこで、「明暗」を時系列的に6つの部分に分けて、津田と他の登場人物の出現分布間の相関を調べてみたのが次のグラフである。
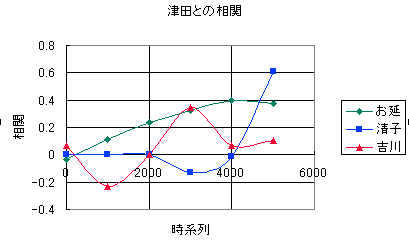 |
このグラフでは、横軸が時系列であり、縦軸が相関を示している。縦軸で上になればなるほど相関が高い、すなわち、「関係がある」のだ。「相関」は本人の場合で「1」である。だから、例えば最後の部分の清子の「0.6」という結果は関係がアリアリということを示しているわけだ。
また、「清子」と「吉川(ここでは夫人を意図している)」の相関が逆であることが面白いだろう。「吉川」が活躍(暗躍?)した後に、「清子」が登場するわけだ。
そして、この「明暗」が盛り上がっていくようすすら、見えてはこないだろうか?全く血の通っていないPCが解析した結果が、漱石の描こうとした「こころ」の動きを読みとっているような気が(少しは)しはしないだろうか?そして、このグラフの延長線上に、漱石の描くはずだった、「明暗」の結末はあるはずなのだ。
さて、このグラフを見ていると、
で計算した恋の多体(三体)問題の計算結果を思い出してしまう。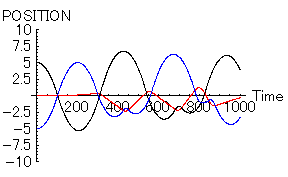 |
漱石は、きっと恋の三体問題を意識しながら「明暗」を書いたのである。だから、ある意味当然なのではあるが、科学と文学の一体化した世界が感じられ、とても面白い気分である。さて、この解析結果を元にして、まだまだ色々とやってみたのであるが、それは次回である。
2001-02-19[n年前へ]
■ひとりで書いてるだけだから。
ヘッポコ文章を直したい
面白い情報を探しにと「お笑いパソコン日誌」を眺めていると、「ウエヤマの事件簿」の「他人の日記をオモチャにしよう!」が紹介されていた。「お笑いパソコン日誌」に〜『できるかな?』風ネタであります〜と紹介されてあった通り、実に私好みの話だった。ウエヤマ氏が「自分で書いてる日記の文章」を解析して、文字の出現頻度を調べてみたものである。
「できるかな?」は画像や科学の関連の話が多いように見える。しかし、実はそれだけではなくて文章や日記に関する話も多い。例えば、これまでに出てきた話を振り返ってみると、
に始まり、- 失楽園殺人事件の犯人を探せ- 文章構造可視化ソフトのバグを取れ - (1999.07.22)
- 「こころ」の中の「どうして?」-漱石の中の謎とその終焉 - (1999.09.10)
- 「星の王子さま」の秘密 - 水が意味するもの- (1999.11.15)
- 恋の力学 三角関係編 - 恋の三体問題- (1999.12.27)
- 恋の力学 恋の相関分析編- 「明暗」の登場人物達の行方 - (2000.04.01)
- 恋の力学 恋のグラフ配置編- 「明暗」の収束を見てみよう - (2000.04.02)
- WEBの世界の「力の法則」-「ReadMe!JAPAN」と「日記猿人」に見るWEBアクセス数分布 - (1999.12.04)
- WEBサイトの絆 - WEBの世界を可視化しよう- (2000.01.13)
そういったhirax.netの特長ならぬ特徴は私が書く文章が下手なせいなわけで、そんなヘッポコ文章から脱出するべく、私の書く文章の特徴を調べて反省してみることにした。もちろん、自分のヘッポコ文章だけを眺めてみてもしょうがない。他の素晴らしい文章を書く書き手と比較しなければならないだろう。そこで、今回はいくつかの文章を品詞解析し、その結果の特徴を調べることにする。そして、書き手による文章の特徴が眺めながら、私のヘッポコ文章の欠点を調べ、さらには誰もが思わず涙がこぼしてしまうような素晴らしい文章を書けるようになりたい、と思うのである。
さて、まずは目標を決めよう。私がヘッポコ文章を脱出してどんな文章を目指すかを、何より先に決めなくてはならない。となれば、あまりにも大それた目標ではあるのだが、やはり日本の文豪、夏目漱石は外せないだろう。そして、その教え子でもある寺田寅彦もやはり外すわけにはいかない。一応私も理系のはしくれ、日本の理系文章の流れを作ったこの二人を目標にしなくてなんとしよう。ヘッポコ文章を脱出していきなり、夏目漱石と寺田寅彦というところに無理があるが、そんなことを考えていては駄目なのである。「少年よ大志を抱け」とクラーク博士も言ったのである。もう少年と言うにはどう考えても年齢的に無理があるのだが、気持ちはまだまだ少年で目標は大きく持ってみたいと思うのである。
そして、もう一人の目標は「ちゃろん日記(仮)」をマイペースに書き続ける「ななゑ」さんである。私は彼女の書く文章を読むたびにとても素晴らしい理系的センスが感じ続けているのである。しかも、理系的でありつつも笑いと涙のペーソスたっぷりの「ちゃろん文体」という独自の確固とした文体を築いているところも尊敬していたりするのである。
というわけで、今回の文章の比較は
- 夏目漱石
- 寺田寅彦
- ちゃろん日記(仮) ななゑ
- 「できるかな?」 jun hirabayashi
- 夏目漱石
- 我が輩は猫である
- 坊ちゃん
- 寺田寅彦
- 科学について
- 自然と生物
- ちゃろん日記(仮)
- 1998(仮)11月上旬
- 1999(仮)6月上旬
- 「できるかな?」
ところで、形態素解析とはどのようなものだろうか。まずは、例を挙げよう。例えば、
私が好きな書き手達は、夏目漱石、寺田寅彦、ななゑさんです。という文章を茶筌で分解すると、
- 私 名詞-代名詞-一般
- が 助詞-格助詞-一般
- 好き 名詞-形容動詞語幹
- な 助動詞
- 書き手 名詞-一般
- 達 名詞-接尾-一般
- は 助詞-係助詞
- 、 記号-読点
- 夏目 名詞-固有名詞-人名-姓
- 漱石 名詞-固有名詞-人名-名
- 、 記号-読点
- 寺田 名詞-固有名詞-人名-姓
- 寅彦 名詞-固有名詞-人名-名
- 、 記号-読点
- ななゑ 名詞-固有名詞-人名-名
- さん 名詞-接尾-人名
- です 助動詞
- 。 記号-句点
- 読点
- 形容詞
- フィラー
- 感動詞
 |
結構、同じ書き手による文章が同じような位置に配置されることがわかると思う。ちゃろん日記(仮)などは、二つの独立した文章がほとんど同じ位置に配置されている。もう、ちゃろん文体は安定しまくっていて完成されているのである。そしてまた、「文豪」夏目漱石の場合も、「我が輩は猫である」と「坊っちゃん」がかなり近い位置に配置されていることがわかる。
なるほど、結構書き手による特徴はこんないかにも雑な解析でも評価できるものなのかもしれない(あくまで「遊び」だけどね)。そして、形容詞の出現頻度などは、「雪だるまがいる景色」と「自然と生物」以外は大体同じようなものである。寺田寅彦の「自然と生物」は妙に形容詞の出現頻度が高いところが面白いところである。私の「雪だるまがいる景色」はあまり技術的な話ではなくて、確かに形容詞が多そうな話ではあるのだが、一体「自然と生物」はどうだっただろうか?
ちなみに、「できるかな?」からの二つの文章は共にフィラーが一個も出てこない。その他の6つの文章にはフィラーが出てくるのであるが、何故か「できるかな?」の二つの文章にはフィラーが含まれていないのである。この差がなければ、寺田寅彦の二編と「できるかな?」はかなり似た場所に位置するのであるが、このフィラーは特に違うのである。
さて、上の図ではフィラーと形容詞の出現頻度だけを眺めてみたが、読点、感動詞の出現頻度も加えて、クラスター分析を行ってみた。つまり、「読点・形容詞・フィラー・感動詞」の出現分布が似ているものを分類してみたわけである。クラスター分析にはExcelアドイン工房「早狩」の統計解析アドインを使用させて頂いた。ちなみに、クラスターの結合はウォード法を用い、非類似度計算法には標準化ユークリッド平方距離を使用した。その結果が下の図である。
 |
このクラスター分析の結果を示す図は近い文章をまとめていったものを示している。つまり、文章の「近さ」あるいは「似ている度」を示しているのである。ちゃろん日記(仮)の二編は本当によく似ていて、また夏目漱石の書いた二編も互いに似ている。そして、それより「近い度」は低いが「新宿駅は電気羊の夢を見るか?」は「科学について」に近くて、「雪だるまがいる景色」は「自然と生物」に近い。おして、さらに似ているものを探せば、ちゃろんの二編と「新宿駅は電気羊の夢を見るか?」・「科学について」は似ているといえなくもない、さらに言えばその四編と夏目漱石の二編が似ている。
ここでは、四人の書き手がいるということが私には判っているので、あえて四つのクラスターに分解してみると、
1.
- 「雪だるま」がいる景色
- 自然と生物
- 新宿駅は電気羊の夢を見るか?
- 科学について
- ちゃろん日記1998(仮)11月上旬
- ちゃろん日記1999(仮)6月上旬
- 我が輩は猫である
- 坊ちゃん
しかし、その一方で考えてみれば寺田寅彦の名随筆と「できるかな?」のヘッポコ文章が「文体が近い」と解析されてしまっているわけなので、実はこの解析の信頼性はかなり低いと言わざるを得ないところもあるのである。いや、もしかしたら「文体は同じやけど、内容が全然違いますがな」というような冷たいアドバイスを解析結果は言わんとしているのかもしれないが、もうそれは哀しすぎる事実なので考えたくないのである。
さて、そう言えば一番最初の図で「できるかな?」と寺田寅彦の差はフィラーの出現分布だったわけであるが、「大学の講義における文科系の日本語と理科系の日本語-- 「フィラー」に注目して --」では、「聞き手への働きかけのあるフィラーが多いということは聞き手への配慮が大きいということにつながる」と書いてあった。ということは、フィラーの出現分布は聞き手への配慮に比例するというわけで、「できるかな?」の文章にフィラーが出てこない、ということは読み手に対する配慮がない、なんてことなのかなと思ってしまったりするのである。
そんなことを考え出すと、ホラどうせひとりで書いてるだけだから読み手のことなんか考えていないのさと、思わず涙がこぼれてしまうような哀しい気持ち、になったのである。う〜む、最初は誰もが思わず涙がこぼしてしまうような素晴らしい文章を書けるようになりたいと思ったったのに、何でこんな結論になるんだろう?
答え: それは文才がないからです。ハイ。
2001-08-07[n年前へ]
■「ボケ」た背景で包み込め
デジカメ画像をキレイにボカそう アルゴリズム編
最近、新しいデジカメを物色中である。私はこれまではFinePix4700zを使っていたのだけど、そのFinePixが半年程度で壊れてしまった。というわけで、C-4040ZOOMがどんなものか期待しているところである。
壊れたFinePixと言えば、そもそも壊れたFinePixは一台ではなかった。私はすでにFinePixを二台も買っているのだ。そして、もうすでに二台とも壊れてしまっているのである。連続殺人事件ならぬ、連続カメラ自殺事件なのである。
まず、一台目に買ったFinePix700ははメキシコのティファナでポケットから落としたら、バッテリーから電源が供給されなくなった。もちろん、ACアダプターを使えば立派に動くのだけれど、それでは少しばかり機動性に欠けてしまう。まさか発電機を持ち歩くわけにはいかないし、コンセントの近くでしか撮影することができないとなると、それは非常に困ってしまう。そこで、すかさず二代目としてFinePix4700zを私は買った。ところが、買ってから半年位たったある日、今度は勤務先の駐車場でポケットから落としてしまった。すると、今度はファインダー視野がズームに連動しなくなって、なおかつレンズがまるでジョイスティックのようにあらゆる方向に曲がるようになってしまった。
こんな風にデジカメはとっても壊れやすくて、半年毎にデジカメ出費を強いられる私に周囲は「落としたオマエが悪い」と非常に冷たいのである。残念なのだ。「そういうのは壊れたんじゃなくて、壊したんだ」と被害者である私をまるで加害者のように告発する人さえいるのである。連続カメラ自殺事件は実は他殺で、しかも犯人は私だと告発する輩さえいるのだ。ひどい話である。
ところで、C-4040に期待しているのは、コンパクトで、レンズアダプターが使えて、レンズがF1.8と明るいことなのである。コンパクトなのは持ち歩くために必要だし、私はなんと言っても超広角デジカメが欲しいのだが、そんなデジカメはないので、ワイドコンバーターを付けたいのでレンズアダプターが必要なのである。明るいレンズの方は、うす暗い中でも撮影する時に重宝しそうなので、少し期待しているのである。
ところで、この位明るいレンズであれば、もう少しぼかすことができるものだろうか?デジカメで写真を撮ってもどうしてもボケない。35mmフィルムを使っているカメラなどと比べるともう全然ボケない。もうほんとにボケない。
例えば、35mmカメラで135mm F4.5開放のレンズなら、ピントの合ってない背景はこの位はボケる。これは京都の哲学の道近くにある吉田山で撮った写真だ。
 |  |
ピントが合っている位置以外は光がボケて、キレイなボケが発生する。どちらの写真も絞りは開放で撮影しているので、後ろの風景はほぼ丸くボケている。ぼかせばキレイというわけではないけれど、背景などがごちゃごちゃしている中で対象物だけを浮き上がらせたい場合には、「ボケ」させるととても良い感じになる。
しかし、デジカメではそうそう簡単にボケた画像を撮影することはできない。35mmフィルムに比べて、CCDサイズが小さいからである。35mmカメラよりAPSカメラはもっとぼけなくて、それよりデジカメはさらにボケないのである。そんな様子を見るために、二台目として買ったFinePix4700zで「ボケ」を意識して撮影してみたものが下の写真である。手前の植物にピントが合って、奥の道の先はボケてはいるのだけれど、それでも先程の写真などとは比べものにならないほどわずかしかボケていない。
 |
ところで、このような画像の「ボケ」を考えるとき、「ボケ」た画像をシャープに復元しようという話は非常にポピュラーな話題である。例えば、本「できるかな?」でもこれまでに
といった感じで遊んできた。また、さらには「恋の形」を復元しようとしたとか、このようなアプローチを遥か昔に考えていた漱石の「文学論」を振り返ってみたりしたきたのである。しかし、これらはいずれも「ボケたデータを復元する」という問題であった。一方、この逆のアプローチである「シャープなデータをボケたデータにする」という問題も結構ポピュラーである。例えば、音楽をホールやライブハウス風にボケた音にするDSPはかなりの数のオーディオ装置に付けられている。これも、もともとはシャープな音声データが部屋の中でボケていく様子をシミュレートする回路である。また、画像に関する話題でも、ピント位置をずらした複数の画像から任意の「ボケ」画像を作成するといった話題もたまに見かける。
そこで、「できるかな?」でもデジカメ画像を35mmカメラ風にキレイにぼかすことに挑戦してみることにした。今回は、まずはアルゴリズムを確認して、次回以降で簡単プログラムを作成してみることにしたい。
まずは、似たようなソフトウェアがあるかどうか、Googleで適当なキーワードを使って検索をかけてみると、IrisFilter(http://www.reiji.net/iris/)というソフトウェアがあった。これは、「写真のぴんぼけを再現する」というフィルターだった。サンプル写真などを見てみると、これがなかなかきれいだった。例えば、早朝の御殿場の路上を「在りし日のFinePix4700z」で撮影した写真にこのフィルタをかけて、「ボケ」を加えてみたのが下の画像である。
 |  |
ここではこんな![]() 六角形の絞り形状をを用いてみた。右の処理画像中の、車のテールランプや車の下部を眺めてみると、鋭いハイライト部が六角形に光っているのがわかだろう。確かに、「ボケ」がカメラの絞り形状になっていて、良い感じである。
六角形の絞り形状をを用いてみた。右の処理画像中の、車のテールランプや車の下部を眺めてみると、鋭いハイライト部が六角形に光っているのがわかだろう。確かに、「ボケ」がカメラの絞り形状になっていて、良い感じである。
WEBページの記載によれば、このIris Filterは「フィルム特性曲線を利用し、レンズから通った光がフィルムを感光させる様子を再現しています」ということである。なんでも、特許も国内・USP共に出願済みということだが、特願2000-100042もU.S.PTO 09/772532も未だ公開にはなっていないようで、残念ながら特許の内容を読むことはできなない。
このWEBページの記述の中で面白いのは、「データ上の数値をそのまま拡散させる従来のPhotoshopをはじめとした画像処理ソフトと違い、実際のフィルムに当たる光の量(露光量)を逆算し、その露光量をもってピントがずれている様子を再現します」という歌い文句でPhotoshopの「ガウスぼかし」と比較広告してある部分である。
試しに、先の画像をIris Filterで「ボケ」を加えた画像と、Photoshopの「ガウスぼかし」とで「ボケ」を加えた画像を比較してみると、下の二枚の画像のようになる。確かにIrisFilterの売り文句通り、こうして比較してみるとPhotoshopガウスぼかしが写真の「ボケ」っぽくないのに対して、IrisFilterの「ボケ」が写真のそれっぽいことが良くわかる。
|  |
さて、お仕着せのソフトを使ってみるだけではなくて、自分でデジカメ画像をキレイに「ボケ」させてみることにしたい。というわけで、hirax.net風「ボケ」フィルターの動作を考えてみる。
まずは、毎度のことだがオリジナル画像が「ボケ」る様子を計算する式は
逆フーリエ変換( フーリエ変換( オリジナル画像 ) x フーリエ変換(ボケ具合 ) )と表すことができる。詳しくは、「宇宙人はどこにいる?」の回でも読んでもらうことにして、簡単に言えば周波数領域でオリジナル画像とボケ具合を掛け算をしさえすれば良いのである。つまり、今回のデジカメ画像をぼかす場合だったら、
- デジカメ画像と「ボケ」具合をそれぞれフーリエ変換し周波数空間に変換
- 周波数空間で乗算を行う
- 逆フーリエ変換して実空間に戻す
じゃぁ、早速やってみようとなるわけだが、その前にもう一つ注意することがある。それは、RGB画像の数値というものは実は元々「明るさを対数変換した値」であるということなのである。人間の目も含めて世の中の大抵の材料は対数的な感度を持っている。例えば、人間の目に「2倍明るい」という場合に、光は「2倍明るい」というわけではない。その場合には指数的にX^2倍明るいのである(ここで、xの値はそれぞれのデバイスによって色々と違う)。その明るさをRGB画像の数値データにする時に、明るさの対数をとってLog[x,X^2]で2という数値として表しているわけだ。
RGB画像の数値が「明るさを対数変換した値」だというようすの一例を示すと下の図のようになる。
横軸 = 0〜255の数値データ 縦軸 = エネルギー  | 横軸 = 0〜255の数値データ 縦軸 = エネルギー  |
逆に明るさからRGB画像の数値データへの変換グラフは例えばこんな感じである。RGB数値で200と255と言っても実はその明るさは大違いであることがわかると思う。
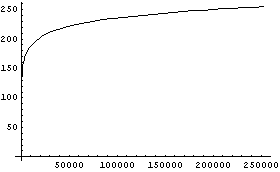 |
だから、この手の処理を行う際には、まずは指数変換してから処理を行い、そしてその後対数変換してやらなければならないわけだ。もちろん、今回のデジカメ画像をぼかす場合にも、RGB画像の数値をまずは指数変換した後、「ボケ」演算を行って、その演算結果を対数変換でRGB画像の数値に戻してやらなければならないのである。といっても、別に難しい話ではなくて画像を扱う装置だとごく当り前の話だ。
そう、「ボケ」演算のhirax.net風レシピはたったこれだけ〜というわけで、早速このレシピに従ってhirax.net風デジカメ「ボケ」フィルターをかけてみたのが下の画像である。キレイな「ボケ」画像ができあがっていることが判ると思う。
 |
ところで、デジカメ画像のRGB画像の数値を指数変換したものに「ボケ」演算を行ったわけだけれど、もしRGB画像の数値そのものに対して「ボケ」演算を行ったら、どんな結果になるだろうか?つまり、「データ上の数値をそのまま拡散させる」やり方をしたら、どうなるのだろうか?そこで、試しにRGB画像の数値そのものに対して「ボケ」演算を行ってみるとこんな結果になる。
 |
何だかボンヤリとにじんだだけの「キレイじゃない」写真になってしまっている。それは、当り前である。本来2倍明るいものはX^2倍明るいわけで、すごく光の量は2倍どころでなく多いわけだ。それが広がる量を仮にRGB数値そのまま2倍として扱ってしまうと、その光の部分は薄暗くなってしまう。コントラストのはっきりしない、ぼんやりとした写真になってしまうわけだ。ちゃんと、X^2倍のデータとして扱ってやらなければならないわけである。
試しに、指数処理したものと線形処理をしたものとを並べてみるとその画像の違いがよくわかるだろう。
キレイなボケ画像(指数処理)  | キレイじゃないボケ画像(線形処理) |
さて、今回はデジカメ画像の「ボケ」フィルターのhirax.net風レシピを確認してみた。次回(と言ってもいつになるか…)以降に、このレシピに従って実際にソフトを作成していこうと思う。
ところで、「文学論」の中で漱石は「ボケ」は焦点的印象又は観念に付随する情緒を意味する、と言っている。それは、言い換えれば「何かの出来事をきっかけとして感じた怒り・悲しみ・喜びなどの感情がボケである」ということだ。そして、さらに言えば、写真で背景をぼかすということは、つまり「背景にある出来事が生みだした怒り・悲しみ・喜びを広く混ぜて包み込む」ということなのである。
だから、何かを撮影する時に対象物の背景をぼかすということは、「背景にある出来事が生みだした怒り・悲しみ・喜びを広く混ぜて対象物を包み込んで、そして対象物を浮き上がらせる」ということなのかなぁ、とぼんやりと考えてみたりする。そんな写真は対象物を写しこんでいるのと同時に、それを包みこむ背景も写しこんでいるンだろうなぁ、と考えてみたりする。
2002-01-20[n年前へ]
■徳川埋蔵金殺人事件
超論理特許ミステリー「狩野埋蔵金の埋蔵場所を解読し発掘する方法」
ワタシの勤務先では「一年に*本特許を書くべし」という恐ろしいノルマがある。もちろん、こまめに書いていれば何の問題もないのだけれど、他の仕事にかまけてついつい後回しにしていたりすると、年末や期末には特許をまとめて書かなければならなくなる。架空の物語を量産する小説家のように、架空の実験データを描き整理し、架空の特許を量産しなければならなくなるのである。
いつものごとく、昨年末もそうだった。年末の最後の二三日は特許書きで追いつめられ、しかも書き上げられずに、できの悪い小学生のように、家へ書きかけの特許を持ち帰って、正月休みに特許を書かなければならなくなったりしていたのである。そんなわけで、正月番組を見ながら、特許庁の電子図書館のサイトにアクセスし特許調査をしつつ特許を書いていた。が、正月番組などを眺めているせいか、どうにもマジメに特許が書けなかったりするのである。いつしか、ビールを飲みながら仕事とは全然関係無い特許公報を眺めていたりしたのである。
今回、紹介する特開2001-42765「狩野埋蔵金の埋蔵場所を解読し発掘する方法」という公開特許公報もその一つである。キャッチーな名前で想像つくとは思うが、なんとこの特許出願はいわゆる赤城山徳川埋蔵金の場所を発掘するための特許なのである。世に出される特許は数多く、埋め立てゴミの数より多いくらいかもしれないが、そんな中でも「埋蔵金の隠し場所を解読し発掘する方法」なんて特許は見たことがない。歴史ミステリー、暗号ミステリー、そして、ご当地モノミステリーなどが好きなワタシは思わず目を奪われ、その特許を読み始め、そしてこの超論理特許ミステリーの世界に引き込まれたのだった。
そして、この特許のあまりの素晴らしさに今回こんな感想文を書いて、世の中にこの超論理特許ミステリー特許を広めたいと思うのである。そして、さらにはこの感想文を読んだ人が特許フォーマットに慣れ親しみスラスラと特許を書けるようになり、ワタシのように特許を書き残しで苦しむ人が減ることを強く望む次第なのである。
さて、特許では、まず「発明の名称」を書かなければならない。この特許でももちろんそうだ。というわけで、
「発明の名称」 狩野埋蔵金の埋蔵場所を解読し発掘する方法
何とも、キャッチーな名前である。これが火曜サスペンス劇場であれば、「徳川赤城山埋蔵金全裸殺人事件2 湯けむり露天風呂で美人女子大生が消えた!村に残る伝説が不気味に今よみがえる!」くらいにはパワーアップすることだろうが、特許の書類としては十分に魅力的である。この名前を見れば、誰しもワタシのようにこの特許の世界に引き込まれるハズである。
そして、次に「どんな範囲のこと」を特許として宣言するかを書くわけだ。これを請求項と呼ぶが、この特許はもちろんこれだ。
「請求項」 従来一般に赤城山徳川埋蔵金といわれている黄金の埋蔵場所を発見・発掘すること
なんと、赤城山徳川埋蔵金といわれている黄金の埋蔵場所を発見・発掘してしまうのである。特許を書いて大金を手に入れるという話はたまに聞くが、特許を書いて埋蔵金を手に入れるという話は聞いたことがない。まさに、夢というか、男のロマンというか素晴らしい特許なのである。
そして、次に「従来の技術」というセクションが続く。つまり、従来はこんな問題がありますよ、こんなに不便だったのですよ、ということを書くのである。それに対して、今回書いたこの技術はそんな「従来の課題」を解決できて、価値があるのですよ、と訴えるのだ。そこで、この特許は説く、
「従来の技術」 従来の技術は、解読に科学性が不足していたために、経済効果の悪いものであった。…暗号のかたちで示されている埋蔵金を資源として再利用するためには、闇雲に探したのでは経済的に成り立たないので技術とは言えない。埋蔵金の探査技術が発達すれば、埋蔵金の発掘は夢や学問でなく産業になるであろう
なんと、これまでの発掘を「技術とは言えない」と喝破しているのである。かつて、近所の埋蔵金伝説に、電子ブロックの金属探知器を頼りに闇雲に探そうとしていたワタシなどは、「あぁ、ゴメンナサイ、ゴメンナサイ…」と謝らなくてはならないような勢いなのである。この作者発明者は埋蔵金の探査技術が発達すれば、埋蔵金の発掘は夢や学問でなく産業になるとまで謳いあげるのだった。今さっき、埋蔵金探しは「夢で男のロマンだぁ」と書いたワタシはさらに「ゴメンナサイ、ゴメンナサイ…」と謝らなければならないのである。
さらに、従来の「埋蔵金探し」を箇条書きに上げ、
- 勘で場所を決めて、縦穴を掘り、さらにいくつもの横穴を掘ったり、ブルトーザーで土を押しのける
- 百年にもわたり、長期間諦めずに掘る
しかし、そんなミステリー特許に引き込まれていくワタシの心の中のツッコミなど知る由もなく、この埋蔵金小説許では、引き続き具体例を挙げて特許の内容を説明していくことになる。それが、次の「実施例」である。具体的な資料群をもとに、埋蔵金発掘に迫るストーリ〜が書き示されている。
が、この資料群がスゴイのである。何しろ、こんな感じなのだ。
- 資料A 「常習赤城におよそ三百六十万両。古井戸を掘ることを手がかりとすべし」という水野家に伝わる遺言
- 資料B 「寺の床下から発見された方位図・地図・暗号文書」
- 資料C 「空井戸から発見した銅板と像」
- 資料D 「黄金埋蔵はアッという間にされたらしい、という地元住人のウワサ」
 |
 |  |
しかも、資料Aの「常習赤城におよそ三百六十万両。古井戸を掘ることを手がかりとすべし」という遺言に対しては、「ここで疑問に思うのは、義父が何故もっと詳しく埋蔵場所を教えなかったのか」などと死者にムチ打ち、マジメなのかそれともツッコミ?と言いたくなるような感想・疑問を書き、この疑問に対して延々2ページに渡り超論理的考察、超心理的考察を加えることで、ついには「埋蔵金は七つの古井戸に埋蔵されたことになる」と、超論理科学的に鉄槌結論を下すのである。
そして、下に示す「寺の床下から発見された方位図・地図・暗号」を基に、黄金分割を始めとする数学的考察などを駆使し、埋蔵金の位置を推定する。しかも、単に推定するだけでなくて、経済的・効率的に発掘をするために埋蔵金の位置の計算誤差を延々と論じて、ついには誤差50cm〜7m弱だと推定するのであった。なるほど、この歴史ミステリー小説特許は単に技術特許にとどまらず、経済を見据えた経済ミステリー特許でもあったのだ。「埋蔵金の発掘は夢や学問でなく産業になる」のだ。
さて、この埋蔵金ミステリーで指し示された「埋蔵金の埋まっている七つの古井戸」がどこであるかを知りたい人も多いだろう。ということで、特許の図を重ね合わせ、埋蔵金の埋まっている七つの古井戸の場所をプロットしてみたのが、次の図である。どの辺りか判らない人のために、広域地図をリンクしておくとここら辺りということになる。
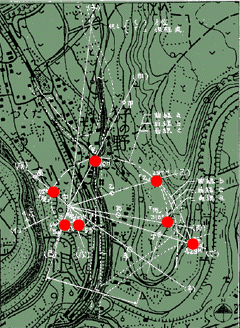 |
さて、この特許の最後には「なお、この辺りは便利な住宅地向きの環境になりつつあるので、住宅が建設される前に発掘することが望ましい」と
と産業としての指針まで描きつつ筆をおくのである。
どうだろうか、面白いミステリー小説特許だったのではなかろうか?そして、特許なんて簡単に書ける、と思った人もいるのではないだろうか?そして、どんどん特許を書きたくなる、と思う人も多いに違いない。で、ワタシは思うのだ。できれば、できることであれば、その書いた特許をワタシにも少し分けて頂いて、ワタシのノルマを少しでも減らして欲しい、と強く強く思うのである。
2002-01-27[n年前へ]
■究極の選択 テキスト編
いつものように自分の英語スキルの無さを実感して、英語の本を読もう、と決めたのです。が、文字の多いものは読めるとも思えないので(自分をよく知っているのだ)、マンガに決めました。が、空港の本屋にあったのは「金田一少年の事件簿」と「部長 島耕作」の二種類だけだったので、しょうがなくストーリーを楽しめそうなモノ、ということでいつもなら絶対に読まない「盗作マンガ」を買いました。はい、「金田一少年の事件簿」を買ったのです。
で、これを読んでいたとき、ふと私は思いました。これ読んで覚えたフレーズとか単語って一体いつ役に立つんだろう?って思ったのです。
私が、周りでやたら殺人事件が起きたり、嵐の山荘に取り残されたりする高校生なら、そんな単語やフレーズを使うシチュエーションは沢山あると思うのです。
でも、残念なことにそんなシチュエーションには私は陥ったことがありません。いえいえ、私どころがほとんどの人はそんなシチュエーションには陥らないと思うのです。これからも、そして未来も。だって、周りでやたら殺人事件が起きる高校生なんてものすごく非現実的な設定です。「死体消失トリック」とか「犯人はオマエだ!」とかいうフレーズを覚えても、きっと何の役にも立たないと思ったのです。
そこで、私はさらに思いました。じゃぁ、私は「部長 島耕作」を選べば良かったのでしょうか?島耕作のようなシチュエーションなら起こりうるのでしょうか?いえいえ、それも絶対に違います。何事にも女性と「良い関係」になり、すべてのピンチをオンナで切り抜けていく出世人生なんて、そうそうないと思うのです。少なくとも、私にそんな状況が訪れるとは思えません。全てを暴力と土下座で切り抜けるサラリーマン金太郎もたいがいですが、全てをオンナで切り抜ける島耕作もひどすぎる設定です。世の中にはこの二種類のサラリーマンしかいないのでしょうか?いいえ、そんなことは無いハズです。何事も切り抜ける道が「暴力・オンナ・土下座」でしか切り抜けられないなんて、それではサラリーマンというよりヤクザ屋さんです。いや、もしかしたら、サラリーマンもヤクザの一種なのかもしれませんが、私はヤクザ屋さんを目指すにはちょっとばかり弱すぎます。
あるいは、島耕作を見習えば、もしかしたらピローロークが上手になるかもしれませんが、それは私の意図するところではありません。それに、島耕作のピローロークが上手いとも私には思えません。私には何で島耕作がモテるのか全然理解できません。あっ、そんなことは関係ないですね。
で、私は思ってしまったのです。殺人事件に囲まれる高校生とかオンナに囲まれる島耕作とか、ありえない設定のマンガは果たして語学力向上の役に立つのか?と。つまりは、出版社の講談社に「オマエはホントに読者の語学力向上を考えているのか」と小一時間問いつめたくなったのです。どうせなら、「某理系ミステリー」とか「動物のお医者さん」とか辺りをお願いしたいのです、ハイ。