2001-02-19[n年前へ]
■ひとりで書いてるだけだから。 
ヘッポコ文章を直したい
面白い情報を探しにと「お笑いパソコン日誌」を眺めていると、「ウエヤマの事件簿」の「他人の日記をオモチャにしよう!」が紹介されていた。「お笑いパソコン日誌」に〜『できるかな?』風ネタであります〜と紹介されてあった通り、実に私好みの話だった。ウエヤマ氏が「自分で書いてる日記の文章」を解析して、文字の出現頻度を調べてみたものである。
「できるかな?」は画像や科学の関連の話が多いように見える。しかし、実はそれだけではなくて文章や日記に関する話も多い。例えば、これまでに出てきた話を振り返ってみると、
に始まり、- 失楽園殺人事件の犯人を探せ- 文章構造可視化ソフトのバグを取れ - (1999.07.22)
- 「こころ」の中の「どうして?」-漱石の中の謎とその終焉 - (1999.09.10)
- 「星の王子さま」の秘密 - 水が意味するもの- (1999.11.15)
- 恋の力学 三角関係編 - 恋の三体問題- (1999.12.27)
- 恋の力学 恋の相関分析編- 「明暗」の登場人物達の行方 - (2000.04.01)
- 恋の力学 恋のグラフ配置編- 「明暗」の収束を見てみよう - (2000.04.02)
- WEBの世界の「力の法則」-「ReadMe!JAPAN」と「日記猿人」に見るWEBアクセス数分布 - (1999.12.04)
- WEBサイトの絆 - WEBの世界を可視化しよう- (2000.01.13)
そういったhirax.netの特長ならぬ特徴は私が書く文章が下手なせいなわけで、そんなヘッポコ文章から脱出するべく、私の書く文章の特徴を調べて反省してみることにした。もちろん、自分のヘッポコ文章だけを眺めてみてもしょうがない。他の素晴らしい文章を書く書き手と比較しなければならないだろう。そこで、今回はいくつかの文章を品詞解析し、その結果の特徴を調べることにする。そして、書き手による文章の特徴が眺めながら、私のヘッポコ文章の欠点を調べ、さらには誰もが思わず涙がこぼしてしまうような素晴らしい文章を書けるようになりたい、と思うのである。
さて、まずは目標を決めよう。私がヘッポコ文章を脱出してどんな文章を目指すかを、何より先に決めなくてはならない。となれば、あまりにも大それた目標ではあるのだが、やはり日本の文豪、夏目漱石は外せないだろう。そして、その教え子でもある寺田寅彦もやはり外すわけにはいかない。一応私も理系のはしくれ、日本の理系文章の流れを作ったこの二人を目標にしなくてなんとしよう。ヘッポコ文章を脱出していきなり、夏目漱石と寺田寅彦というところに無理があるが、そんなことを考えていては駄目なのである。「少年よ大志を抱け」とクラーク博士も言ったのである。もう少年と言うにはどう考えても年齢的に無理があるのだが、気持ちはまだまだ少年で目標は大きく持ってみたいと思うのである。
そして、もう一人の目標は「ちゃろん日記(仮)」をマイペースに書き続ける「ななゑ」さんである。私は彼女の書く文章を読むたびにとても素晴らしい理系的センスが感じ続けているのである。しかも、理系的でありつつも笑いと涙のペーソスたっぷりの「ちゃろん文体」という独自の確固とした文体を築いているところも尊敬していたりするのである。
というわけで、今回の文章の比較は
- 夏目漱石
- 寺田寅彦
- ちゃろん日記(仮) ななゑ
- 「できるかな?」 jun hirabayashi
- 夏目漱石
- 我が輩は猫である
- 坊ちゃん
- 寺田寅彦
- 科学について
- 自然と生物
- ちゃろん日記(仮)
- 1998(仮)11月上旬
- 1999(仮)6月上旬
- 「できるかな?」
ところで、形態素解析とはどのようなものだろうか。まずは、例を挙げよう。例えば、
私が好きな書き手達は、夏目漱石、寺田寅彦、ななゑさんです。という文章を茶筌で分解すると、
- 私 名詞-代名詞-一般
- が 助詞-格助詞-一般
- 好き 名詞-形容動詞語幹
- な 助動詞
- 書き手 名詞-一般
- 達 名詞-接尾-一般
- は 助詞-係助詞
- 、 記号-読点
- 夏目 名詞-固有名詞-人名-姓
- 漱石 名詞-固有名詞-人名-名
- 、 記号-読点
- 寺田 名詞-固有名詞-人名-姓
- 寅彦 名詞-固有名詞-人名-名
- 、 記号-読点
- ななゑ 名詞-固有名詞-人名-名
- さん 名詞-接尾-人名
- です 助動詞
- 。 記号-句点
- 読点
- 形容詞
- フィラー
- 感動詞
 |
結構、同じ書き手による文章が同じような位置に配置されることがわかると思う。ちゃろん日記(仮)などは、二つの独立した文章がほとんど同じ位置に配置されている。もう、ちゃろん文体は安定しまくっていて完成されているのである。そしてまた、「文豪」夏目漱石の場合も、「我が輩は猫である」と「坊っちゃん」がかなり近い位置に配置されていることがわかる。
なるほど、結構書き手による特徴はこんないかにも雑な解析でも評価できるものなのかもしれない(あくまで「遊び」だけどね)。そして、形容詞の出現頻度などは、「雪だるまがいる景色」と「自然と生物」以外は大体同じようなものである。寺田寅彦の「自然と生物」は妙に形容詞の出現頻度が高いところが面白いところである。私の「雪だるまがいる景色」はあまり技術的な話ではなくて、確かに形容詞が多そうな話ではあるのだが、一体「自然と生物」はどうだっただろうか?
ちなみに、「できるかな?」からの二つの文章は共にフィラーが一個も出てこない。その他の6つの文章にはフィラーが出てくるのであるが、何故か「できるかな?」の二つの文章にはフィラーが含まれていないのである。この差がなければ、寺田寅彦の二編と「できるかな?」はかなり似た場所に位置するのであるが、このフィラーは特に違うのである。
さて、上の図ではフィラーと形容詞の出現頻度だけを眺めてみたが、読点、感動詞の出現頻度も加えて、クラスター分析を行ってみた。つまり、「読点・形容詞・フィラー・感動詞」の出現分布が似ているものを分類してみたわけである。クラスター分析にはExcelアドイン工房「早狩」の統計解析アドインを使用させて頂いた。ちなみに、クラスターの結合はウォード法を用い、非類似度計算法には標準化ユークリッド平方距離を使用した。その結果が下の図である。
 |
このクラスター分析の結果を示す図は近い文章をまとめていったものを示している。つまり、文章の「近さ」あるいは「似ている度」を示しているのである。ちゃろん日記(仮)の二編は本当によく似ていて、また夏目漱石の書いた二編も互いに似ている。そして、それより「近い度」は低いが「新宿駅は電気羊の夢を見るか?」は「科学について」に近くて、「雪だるまがいる景色」は「自然と生物」に近い。おして、さらに似ているものを探せば、ちゃろんの二編と「新宿駅は電気羊の夢を見るか?」・「科学について」は似ているといえなくもない、さらに言えばその四編と夏目漱石の二編が似ている。
ここでは、四人の書き手がいるということが私には判っているので、あえて四つのクラスターに分解してみると、
1.
- 「雪だるま」がいる景色
- 自然と生物
- 新宿駅は電気羊の夢を見るか?
- 科学について
- ちゃろん日記1998(仮)11月上旬
- ちゃろん日記1999(仮)6月上旬
- 我が輩は猫である
- 坊ちゃん
しかし、その一方で考えてみれば寺田寅彦の名随筆と「できるかな?」のヘッポコ文章が「文体が近い」と解析されてしまっているわけなので、実はこの解析の信頼性はかなり低いと言わざるを得ないところもあるのである。いや、もしかしたら「文体は同じやけど、内容が全然違いますがな」というような冷たいアドバイスを解析結果は言わんとしているのかもしれないが、もうそれは哀しすぎる事実なので考えたくないのである。
さて、そう言えば一番最初の図で「できるかな?」と寺田寅彦の差はフィラーの出現分布だったわけであるが、「大学の講義における文科系の日本語と理科系の日本語-- 「フィラー」に注目して --」では、「聞き手への働きかけのあるフィラーが多いということは聞き手への配慮が大きいということにつながる」と書いてあった。ということは、フィラーの出現分布は聞き手への配慮に比例するというわけで、「できるかな?」の文章にフィラーが出てこない、ということは読み手に対する配慮がない、なんてことなのかなと思ってしまったりするのである。
そんなことを考え出すと、ホラどうせひとりで書いてるだけだから読み手のことなんか考えていないのさと、思わず涙がこぼれてしまうような哀しい気持ち、になったのである。う〜む、最初は誰もが思わず涙がこぼしてしまうような素晴らしい文章を書けるようになりたいと思ったったのに、何でこんな結論になるんだろう?
答え: それは文才がないからです。ハイ。
2001-04-29[n年前へ]
■ファイト!縦文字文化
縦と横の解像度を考えよう
今年も去年に引き続き英語研修を受けている。といっても、去年は毎日十五分の英語研修だったが、今年は週二日のものを二種類受けている。何事も、「一番弱いところを強くするのが一番」というわけで、それが私の場合は英語であるわけだ。いや、もちろん弱いところは数え切れないほどあるのだが、英語はもうどうしようもないくらいダメなのである。
その英語研修を受ける中で、本当に実感するのが「頭の中でも英語で考えないとキツイ」ということである。頭の中で日本語で考えてから英語で喋ろうとすると、その「日本語→英語変換」のオーバーヘッドはすさまじくて、とても会話にならないのである。もちろん、当然その逆もしかりで「英語→日本語変換」なんかもやっていたら、あっというまに相手の喋るスピードについていけず、「ここはどこ?私はだれ?」状態になってしまう。
もちろん、「頭の中で英語で考えられる位なら、そもそも苦労はせんのじゃぁ!」と叫びたくなることもしばしばあるわけで、実際のところ私にはどうしたら良いのか全然わからないのである。「頭の中に言いたいことは沢山あるけど、それを伝えられない状態」と「頭の中でたいしてものを考えることができない、それを伝えられる状態」とどっちかを選べと言われても困ってしまう。残念ながら、「英語で頭の中でビュンビュンと考えて、それが口からペラペラとでてくる」状態は私には遠い夢物語のようなのである。
こんな苦労は、日本語人生一本やりだった私が英語を使う場合にはどうしても避けられない話なのであるが、そんな「私の苦労」と似たような話はコンピュータの世界にも実はある。例えば、「今日の必ずトクする一言」でもよく登場する「Windowsの日本語化のオーバーヘッドに関する一連の話」などがそうである。超漢字あたりであれば話は別なのかもしれないが、Windowsに限らずどんなOSであっても英語だけを使うときと、日本語のような言語を使うときではスピードが全くと言って良いほど違ってしまう。
例えば、英語版のWindowsであれば最新型のPCでなくてもサクサク動くのであるが、これが日本語版のWindowsともなると、最新型のPCでなければカタツムリのようなスピードに変わってしまうのである。最新型のWindowsやMacOS***の推奨マシンスペックは○×○×です、とOSメーカーが言ったところで、それは英語圏での話で日本語人生の私のようなものにはそれは当てはまらないのだ。わずか100文字ほどのアルファベットですむ英語の場合と、約七千字ほどもある日本語を使う場合とでは文字・フォント処理のスピードが違ってしまうのは当たり前の話である。
ところで、英語と日本語をコンピューターなどで扱う時の大変さというものは文字数だけの話なのだろうか?数が多いから大変なのは当たり前なのだが、それだけではないのではないだろうか。単に文字数が多いというだけではなくて、一つの文字当たりの情報量も日本語の方が遙かに多いと思うのである。例えば、アルファベットの中でも複雑な形をしている"M"と、日本語というか漢字の中でも結構複雑な形をしている「廳」を比べてみれば一目瞭然だろう。"M"よりも、「廳」の方がずっと複雑な形状をしている。
漢字の文字数が多いということは、そのたくさんある文字を区別するためにも漢字という文字の形状自体が複雑にならざるをえないわけで、それはすなわち漢字一文字の情報量はアルファベット一文字の情報量よりも遥かに多いということだ。ということは、
- 一文字辺りの情報量が多くて
- しかも文字数が多い
しかし、「PC内部での処理も大変ではあるが、それを外部に出すときも大変だろう」というのが今回の話のテーマである。モニタやプリンタに出力する時の大変さも英語と日本語では大違いで、しかも英語文化で考えると見えない落とし穴があるのではないだろうか、という話である。
まず、文字を表示するスペースというのは大体決まっている。そんな限られた同じスペースの中に、一文字辺りの情報量が少ないアルファベットと多い漢字を同じように詰め込めるだろうか?先ほどの"M"と「廳」を縮小して10pt程度にしてみると、その答えはすぐにわかる。アルファベットの"M"の方はちゃんと読めるとは思うが、漢字の「廳」の方がちゃんと識別できる環境の人がいるだろうか?PCの画面に表示されている「廳」はずいぶんと省略されたてしまっていたり、あるいは潰れてしまっていたりするはずである。
つまりは、PCの内部でも漢字のような文字を扱うのは大変であるが、それを外部へ表示したりするのも実際問題大変なのである。英語圏のアルファベット文化から考えれば、10ptなんて大きくて読みやすいと思うのかもしれないが、漢字などを考えると今のモニタの解像度では10ptでも小さすぎるのである。逆にいえば、アルファベットなどを表示する時に比べて漢字などの文字を表示する時には、遥かに高い解像度のモニタが必要とされるのである。PC自体の能力だけではなくて、モニタなどの出力機器も遥かに高い能力が必要とされるわけだ。
もちろん、それは漢字だけの話ではない。世界中の文字で当てはまるハズの話である。試しに、
- 世界の文字 (http://www.nacos.com/moji/)
 |  |  |
 |  |  |
アラビア文字あたりはラテン文字であるアルファベットと同じ程度の複雑さであるが、その他の文字はやはり遥かにアルファベットよりも複雑な形状をしている。「この中の半分くらいは使われていない文字じゃねぇーか!」という声も聞こえてきそうな気もするが、そんな小さいことを気にしてはいけない、とにかくアルファベットは色々ある文字の中でも単純な形状をしていて、漢字は複雑な形状をしているのである。
次に、それぞれの文字画像の複雑さの特徴を眺めるために、それぞれ二次元フーリエ変換をかけて、周波数空間に変換してみたものを示してみることにしよう。まずは、漢字の例を示して図の見方を説明してみたい。
 | 図の横・縦方向が実際の文字の横・縦方向に対応し、図の中で中央から外周方向に向かって低周波から高周波の成分の量を示している。強さは 小 ← 赤 黄 黄緑 青 紫 → 大の順番になっている。 たとえば、この漢字の例だと |
上の説明に書いたように、こんな風に文字画像を周波数空間に変換すると、「漢字は縦と横の線が多い」ということがよくわかる。しかも、
の時に調べたように、漢字は「縦方向に周波数成分が多い」、すなわち言い換えれば「横方向の線が多い」こともわかるのである。 さて、世界の文字六種に戻って、それぞれを周波数空間に変換して並べてみると、こんな感じになる。
 |  |  |
 |  |  |
こうして六種の文字種を周波数空間に変換して眺めてみると、色々なことが判る。例えば、
- アラビア文字はほとんど高周波を含まない
- ヒエログラフは比較的高周波が少なく、方向性も持たない
- 漢字に含まれる高周波成分はほとんどが縦・横方向のみであり、その中でも「縦方向に周波数成分が多い」、すなわち言い換えれば「横方向の線が多い」
- アルファベットは低周波がメインであり、縦横では横方向の方が高周波を含んでいる、すなわち縦の線が多い
- マヤ文字は一番高周波まで含んでおり、比較的方向性も少ない
- ロンゴロンゴ文字はアラビア文字よりも高周波が多いが、それでも比較的低周波メインであり、方向性もない
もちろん、ラテン文字が比較的高周波が少ないからといって今の表示装置で十分だというわけではなくて、ラテン文字でもより高解像度のディスプレイが必要とされている。例えば、液晶画面などで文字を多量に読むことを想定している電子ブックなどの用途のためには、
で調べたMicrosoftの「ClearType」などの技術がある。これは液晶のRGBの画素の配列が横方向に並んでいることを利用して、横方向の解像度を高める技術である。ということは、こういう技術は横方向の高周波成分が多いラテン文字などでは効果が大きく、またラテン文字自体が比較的高周波成分が少ないために、こういう技術を使えば必要十分ということになるのかもしれない。しかし、日本語(漢字)のようなもともと高周波成分が多くしかもそれが縦方向に多い、というようなものでは効果は比較的少ないことが考えられる。もちろん、それは液晶というデバイスの特徴によるもので仕方のない部分もあるのだが、もしかしたらもしかしたら日本語のような縦方向の高周波を再現しなければならない言語のことを意識していないせいかもしれない。
こんなことは液晶などのモニタだけではなくて、一般的なプリンタもそうだ。例えば、インクジェットプリンタではエプソンのPM-900Cの仕様などを眺めてみても、標準で720×720dpiで、高画質モードでは1440×720dpiとなっている。それはレーザービームプリンタなどでも同じで、リコーのプリンター大百科からウルトラスムージングテクノロジーを見てみても、やはり横方向の解像度のみを高めて2400dpi×600dpiとなっている。やはり、プリンタなどの印字装置でも横方向の解像度を高めようとはするが、縦方向の解像度は低いままにしているのである。もちろん、縦方向の解像度を高くすると印字速度が遅くなってしまうという、プリンタの特性があるにしても、やはり日本語を印字するためには不利な設定となっているのである。日本人としては、解像度表示は縦方向を重視するべきで、横方向の解像度表示にダマされるべきではないのである。高解像度2400dpiなんて言われても、「ヘヘン、オレは縦文字文化の日本人だから関係ないんだもんね」くらいは言って欲しいわけである。
実際のところ、せっかく日本語(漢字)を使うのだから、日本語の特性に応じたPCやモニタやプリンタがあっても良いのになぁ、と思う。いや、というより日本語の特性をもっと理解するところから始めなければならないのかもしれない。そうだ、私はまずは日本語の勉強から始めるべきなのだ。英語の勉強をしている場合ではないし、頭の中で英語で考えていたりすると、縦文字文化に合った発想ができなくなってしまうに違いないのである。って、英語学習から逃げてるだけだったりして…
あぁ、しまったぁ。今回はホントに真面目な話になってしまったぞ、と。しかも、まるで国粋主義者みたいだし。
2001-10-16[n年前へ]
■「分光的に近い色」
「分光的に近い色」でない場合の問題点は、そこにあたる光の波長分布が違うと色が合わなくなってしまうことが一つあります。昼間の光で色が合っているように見えても、夕日があたった途端に塗りなおした個所が丸判りなわけです。
でもって、もうひとつの問題点は「自分の目」は人によって個性があってそれぞれ違うわけです。だから、たかだか三次元に情報が減らされた「自分の目」で合わせたつもりになっている時には、「他の人にはきっと違う色に見えているんだ」と意識することを忘れないようにしたいな、と思うわけです。 「分光的に近い色」の場合には、自分の目を直接的には介さないかもしれませんが、そのかわりに「一見、機械的には見えるけれども」他の光りがあたっている場合や、他の人の目で眺めた場合のことも意識できるのが良いところかもしれないですね。
とはいえ、私も自分の目で作ってく作業は大好きですよ。えぇ、もちろん。ただ、「自分の目はみんな違う」っていうのがちょっと頭のすみにあるってだけで。
2002-02-03[n年前へ]
■映画のフィルムを並べたスクラップ
映画大好きの「元」少年少女達へ
先日、「お笑いパソコン日誌」で3次元画像ブラウザ「みょう絵」というものを知った。画像ファイルを日付や色の特徴などで三次元空間に並べてみる、というソフトだ。下の図がその「みょう絵」の動作画面だけれど、こんな風に三次元空間に配置された画像が散らばる中を「みゅぃーん」と動く感覚が結構気持ち良い。
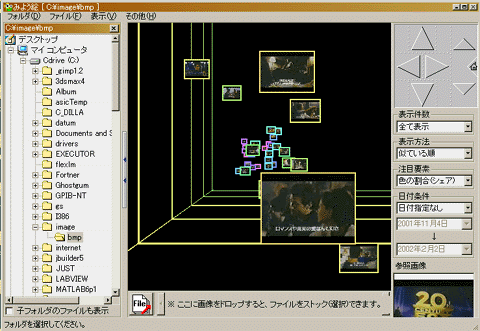 |
で、その「みょう絵」をいじって
欲を言えば画像だけでなくて、色んな文章や音楽や気持ちとか、世の中のありとあらゆるものをこんな風にして眺めてみたいなぁ、と思った。あのころ撮影した写真や、眺めた景色や、読んだWEBサイトや…、とにかくありとあらゆるものを。と思った。すると、「お笑いパソコン日誌」のChic氏が
余談ですが、Windows XP はムービーファイルをサムネイル化してくれるんですが、あらゆるファイルをそうしてくれればいいのにと思ったり。と書いていた。それを読んで、「みょう絵」で一本の映画の中を覗いてみたいなぁ、と思ったのである。
映画が展開していくそのストーリーの時系列と、その中の色々な各舞台を三次元的に眺めてみたいと思ったのだ。そして、さらにはその映画の世界の中を三次元的に散策してみたいと思ったのである。
もちろん、それは映画の動画ファイルを静止画に展開して、それを「みょう絵」で開けばよいだけの話である。以前、動画ファイルを静止画に展開するアプリケーションを作ったこともある。
とはいえ、それを使って映画をキャプチャーしたファイルをそのまま静止画に展開するわけにはいかない。そんなことをしたら、ものスゴイ数の静止画ができてしまうからだ。1秒あたり約30枚もの静止画を含む動画をそのまま静止画に全部落としたら、一体どれだけのファイルができるだろうか?たった2分位の映画の予告編だって、展開したら何と3600枚である…。これだけの画像を読みこませたら、少なくとも私の遅いPCでは「みょう絵」がストライキを起こすことは確実だ。
そこで、映画の動画ファイルの中から、場面が変わるごとに一枚づつ静止画を抽出してみることにした。そうすれば、映画の中の色々な場面をそれぞれ一枚づつの画像として眺めることができる。そして、その画像を集めれば、その映画の色々な場面を一枚のノートにして見ることができるわけである。
というわけで、作ってみたのがこのAVI2Stillsである。いつものように、テキトーに仕立て上げただけだ。下の図がAVI2Stillsの動作画面である。ちなみに、この画面中で、TrigerLebelは場面変化を検出する感度を示すパラメータで、多分60位が適当だと思う。そして、SkipFrameは動画ファイルの中を何フレーム毎に調べていくかを示すパラメータである。展開スピードが気にならなければ1でも構わない。
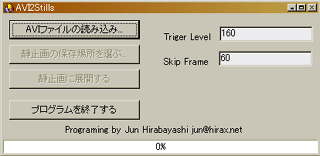 |
このソフトができたところで、試しに - ロケット制作に憧れる少年達を描いた「遠い空の向こうに」"OctoberSky"( = 原作 "Rocket Boys"のアナグラム) - の中の各場面を抽出してみたのが下のスクラップである。予告編の中の各シーンが絵コンテのように抽出され、並べられていることが判ると思う。
 |
こんな風に自分の好きな映画の場面を全部テキトーに抽出して、あとは「みょう絵」で眺めてみれば、その映画の世界を三次元的に散歩できるのである。というわけで、北村薫原作の映画「ターン」の予告編の世界を「みょう絵」で眺めてみたのが下の図である。
 |
静止画では判りにくいけれど、立体的に配置された「映画空間」の中を散策してみるのは、やはりちょっと面白い。これで、欲を言えば各場面に近づくとその場面で流れていた音楽やセリフが聞こえてきたら、面白いと思う。それは、ムソルグスキーの「展覧会の絵」のようで気持ちが良いはずだ。そして、そうすれば気持ちが良いだけではなくて、今の「みょう絵」に足りない「画像だけではない何かをも眺めること」ができるわけだ。
またせっかくだから、「みょう絵」で眺めて終わりにするのも少しもったいないので、以前作った写真アルバム風のスクリーンセーバー"FilmStrip99"(手元のWindows2000では手直しが必要みたいだが…)で、白黒写真のコンタクトフィルム風のスクリーンセーバーを動かしてみた。それが下の画像である。映画のフィルムでなくて、写真のフィルム風だというところはご愛敬で許して欲しい。ちなみに、下の一連の画像は"SomeoneLike You"「恋する遺伝子」の予告編から変換したものである。
こんな風に自分の好きな映画の予告編などを使って自分用のスクリーンセーバーを作ってみるのも面白いと思う。今なら、たくさんの映画の予告編にオンラインでアクセスできるし、その予告編の動画ファイルがもしmov形式ならmov2aviを使って、それがもしrealvideo形式ならTinraを使えば、AVIファイルに変換できる。そして、今回のAVI2Stillsを使えば良いだけなのである。
 |
ところで、こんな切り取った映画のフィルムを繋いだ一連のシーンといえば、ニューシネマパラダイスのラストシーンを思い出す。アルフレードの遺品、「主人公が覗き見ていた一連の場面」を繋いだシーンのフィルム、に主人公が涙したように、かつて少年少女だった映画大好きの人達がそれぞれ自分用のそんなスクラップフィルムを作ってみるのも面白いかも、と思う。そして、ふと思うことがあった時に眺めてみるのも、趣があるかも。
2002-02-20[n年前へ]
■「やおい」の評価演算子
ベクトルの彼方で待ってて II
 東京駅近くの飲み屋「美少年」で、日本酒利き酒セットを目の前にしながら、私は珍しく「日本の政治」について話していた。といっても、単にそれは話し相手が社会部に属する新聞記者だったからである。で、その時の話題は小泉首相と福田官房長官の話だったろうか?
東京駅近くの飲み屋「美少年」で、日本酒利き酒セットを目の前にしながら、私は珍しく「日本の政治」について話していた。といっても、単にそれは話し相手が社会部に属する新聞記者だったからである。で、その時の話題は小泉首相と福田官房長官の話だったろうか?
「福田X小泉っていうのは、結構上手くやっているのかな?」と私が言うと、おもむろに
「あれは、福田X小泉じゃなくて、絶対あれは小泉X福田なのー」とその記者が言ったのである。何を言っているのかその意味がよく判らないまま、「ん〜?」と私が首を傾げていると、繰り返し
「福田X小泉と小泉X福田は全然意味が違うのー」と言い始めるのである。何が何だか訳がわからない。じゃぁ、何か?小泉X福田だと小泉純一郎が総理大臣で福田康夫が官房長官だけど、福田X小泉だと福田康夫が総理大臣で小泉純一郎が官房長官になるとでも言うのか??政治の世界では、言う順番で総理大臣が決まるとでも言うのか?と私が口をはさむと、
「そう。ただ、ちょっと政治の世界とは違う世界かも〜。政界じゃなくて、やおい界ではー。」と言うのだ。なんだコイツ?政界は判るけど、やおい界って一体何処の世界の話だ??と、困惑する私も構わず、そこから延々と長い演説が始まった…。その大河ドラマのようにやたらと長い話を要約すると、
- やおい → 一部の女性が好む「男性同士の恋愛もののストーリー」のこと
- X → やおいの世界で恋愛の関係を示す記号。例えば、AさんとBさんが恋に落ちるであれば、Aさん×Bさんと表す。で、ここで重要なのは先に位置する方が「攻め役」となって、後に位置する方が「受け役」となる…。つまり、例えばサド侯爵とレオパルド・マゾッホであれば攻め役がサド侯爵で、受け役がマゾッホなので、サド×マゾなのである。決して、マゾ×サドではない…
で、日本酒を飲みながら、まだまだ続くその話に悪酔いしていると、「カップルの順序が重要なんだー」という言葉を聞いて、ふと中学の頃の数学の授業を思い出した。その頃、大学を出てまだ一年目の斉藤慶子似の数学の先生と話していたときに、「Hくん、あのね掛け合わせる順序が違うと結果も違っちゃう計算もあるのよ」と教わったことがあった。そんな言葉から私は未知の「数学の世界」をかいま見たりしたのである。 今考えてみれば、新任の斉藤慶子似の女性教師の個人授業なのだから、行列・ベクトルの掛け算の順序なんかじゃなくて、「もっと違う順序」を手取り足取り教えてくれても良かったんじゃないか、とか思ったりするし、そうすれば、私は未だ見ぬ「大人の世界」を覗き見ることができたのではないか、と思ったりもするのだけれど、そんなことは残念ながら無くて、私はただ「行列・ベクトルの世界」を覗いただけだったのである。
で、そんな昔話を思い出したせいか、頭の中でこんな風に思ったのである。そういえば、これまで「できるかな?」では数多く「恋の力学」でも遊んできた。ただ、そこでは「惹かれ合う恋心の大きさ」だけに注目して、そのカップルの中での役割などは考えたことがなかった。そこで、今回は「やおい」のカップルの「役割・順序」に注目し、その「役割・順序」を評価する演算子を行列・ベクトルの掛け算になぞらえながら考えてみることで、これまでと同じく色々な「恋の形」を眺めてみたいと思う。
まずは、色々な人物(実際の人物であったり、小説などの登場人物であったり)のタイプを二次元空間に配置しよう。「この人は結構攻め役が合いそう」とか「この人は絶対受け役が合うのだー」という適性を
- 攻めベクトル
- 受けベクトル
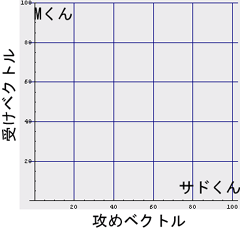 |
そして、カップリング適性では「A×B、B×Aが全然違う」ということから、外積(ベクトル積)をそのまま流用して、適当な評価関数を作ってみるのが自然だろう。まず、
カップリング適性ベクトル = (攻め度(s)、受け度(m))と表記して、例えばAさんのカップリング適性ベクトルを(As, Am)と表すことにしてみよう。すると、Aさんが「攻め」でBさんが「受け」のカップリング適性は、この二人の適性ベクトルのベクトル積として表すことができる。つまり、
A×Bのカップリング適性 = ( As * Bm - Am * Bs )となるわけである。式を眺めれば判るように、Aさんの攻め度が高くて、Bさんの受け度が高ければ、この評価関数は高い値を返す。つまり、「A×Bの順序は正しいのだー」という評価を返す。つまり、「A×B」はなかなか良いカップルだー、と教えてくれる。また、もしAさんの受け度が高くて、Bさんの攻め度が高ければ、低い値を返す。つまり、「A×Bの順序は絶対間違ってるのだー」と評価してくれるのである。なんともありがたいことに(いや別にありがたくはないか…)、この「やおいのカップリング評価演算子」が「福田X小泉」と「小泉X福田」のどちらが自然なのかを教えてくれるのだ。試しに、上のサドくんとMくんであれば、「サドくん×Mくん」= (100,0)×(0,100) = 100*100 - 0*0 = 10000でとっても「良い感じ」でああるが、「Mくん×サドくん」= (0,100)×(100,0) = 0*0 - 100*100 = -10000で「このカップリングは絶対順序が違うー」と判るわけである。
= Aさんの攻め度 * Bさんの受け度
- Aさんの受け度 * Bさんの攻め度
とりあえず、今回はこの評価演算子を作成するところまでで終えたいと思うが、いずれこの「やおいの評価演算子」を武器にして、いつか(?)「やおいの世界= やおい界」に限らず、色んな数多くの恋の関係を目に見えるようにしてみたいと思う。そして、これまで数多く考えてきた「恋の〜シリーズ」を充実させていきたいと思うのである。
ところで、今回のカップリング適性評価演算子は基本的に外積そのものである。つまり、この演算が返す値は「二人のベクトルでできる平行四辺形の面積」に等しい。つまりは、「二人のベクトルでどれだけ色んな違うことがきでるか」を示す尺度である。そして、その値は二人のベクトルが直交する時、すなわち二人のベクトルが重ならず独立である時に最大値となる。つまりは、「二人のベクトルが違えば違うほど大きく」なる。例えば、先の「サドくん×Mくん」であれば二人のS,M趣向が完全に正反対であったからとてもお似合いのカップルになったのである。
これをいわゆる恋の話で考えてみると、とっても独立な二人、趣味が重ならない二人がお似合いだということになる。なるほど、そんなカップルも世の中にはたくさんいることだろう。そんな人達を「外積タイプのカップル」と呼ぶことができると思う。
一方、趣味が重ならないカップルだけでなくて、世の中にはそれとは正反対の「趣味が重なる良いカップル」も数多くいる。それは「内積タイプのカップル」である。内積はA,Bベクトル間の正射影に比例する量であって、つまりは「二人の重なるベクトルの大きさ」である。それは例えば、相手の中に自分を重ね合わせるような「二人の重なる部分が二人を結びつけるようなカップル」なのである。
「理系と文系」・「男と女」が対極的なものでも、相反するものでもないのと同じく、「外積カップルと内積カップル」も別に二つに分けられるようなものではないだろう。「外積タイプの恋」も「内積タイプの恋」が混じり合って、それぞれに良いところもあれば、危ういところもあって、などと想像してみるのも面白いに違いない。そして、さらにはもしかしたらベクトル空間で萌えることができるようになったりするかもしれない。
そういえば、ふと考えてみると以前「恋の形を見た人は」で最後に引用した本橋馨子の「兼次おじ様シリーズ」は男性同士の恋の話だった。つまりは「やおい」の話だった。そこで、もう一度そのセリフを最後に飾って眺めてみようと思うのである。
「愛はどんな形をしているか知っているか?」「見た事ないからわかりません。」「そうだ、誰も見た者はないのに、誰もが当然のように形づけて受け入れている...
もし愛に優劣を決めるものがあればなんだろう?... 異性愛か、同性愛か、そんなものじゃない …たとえ、どんな形だろうと選ぶのはおまえ自身だよ。」